Mathematical expectation of a continuous random variable. Solution example. Continuous random variables Given the distribution function of a continuous random variable x
2. DESCRIPTION OF UNCERTAINTY IN DECISION-MAKING THEORY
2.2. Probabilistic-statistical methods for describing uncertainties in decision theory
2.2.4. Random variables and their distributions
Distributions of random variables and distribution functions. The distribution of a numerical random variable is a function that uniquely determines the probability that a random variable takes a given value or belongs to some given interval.
The first is if the random variable takes on a finite number of values. Then the distribution is given by the function P(X = x), giving each possible value X random variable X the likelihood that X = x.
The second is if the random variable takes on infinitely many values. This is possible only when the probability space on which the random variable is defined consists of an infinite number of elementary events. Then the distribution is given by the set of probabilities P(a <
X
P(a <
X
This relationship shows that both the distribution can be calculated from the distribution function, and vice versa, distribution function- by distribution.
Used in probabilistic-statistical decision-making methods and others applied research distribution functions are either discrete or continuous, or combinations thereof.
Discrete distribution functions correspond to discrete random variables that take on a finite number of values or values from a set whose elements can be renumbered by natural numbers (such sets are called countable in mathematics). Their graph looks like a step ladder (Fig. 1).
Example 1 Number X of defective items in the batch takes the value 0 with a probability of 0.3, the value 1 with a probability of 0.4, the value 2 with a probability of 0.2 and the value 3 with a probability of 0.1. Graph of the distribution function of a random variable X shown in Fig.1.
Fig.1. Graph of the distribution function of the number of defective products.
Continuous distribution functions do not have jumps. They increase monotonically as the argument increases, from 0 for to 1 for . Random variables with continuous distribution functions are called continuous.
Continuous distribution functions used in probabilistic-statistical decision-making methods have derivatives. First derivative f(x) distribution functions F(x) is called the probability density,
The distribution function can be determined from the probability density:

For any distribution function
and therefore

The listed properties of distribution functions are constantly used in probabilistic-statistical decision-making methods. In particular, the last equality implies a specific form of the constants in the formulas for the probability densities considered below.
Example 2 The following distribution function is often used:
 (1)
(1)
where a and b- some numbers a . Let's find the probability density of this distribution function:

(at points x = a and x = b function derivative F(x) does not exist).
A random variable with distribution function (1) is called "uniformly distributed on the interval [ a; b]».
Mixed distribution functions occur, in particular, when observations stop at some point. For example, when analyzing statistical data obtained using reliability test plans that provide for the termination of tests after a certain period of time. Or when analyzing data on technical products that required warranty repairs.
Example 3 Let, for example, the service life of an electric light bulb be a random variable with a distribution function F(t), and the test is carried out until the light bulb fails, if this occurs less than 100 hours from the start of the test, or until the moment t0= 100 hours. Let G(t)- distribution function of the operating time of the lamp in good condition in this test. Then

Function G(t) has a jump at a point t0, since the corresponding random variable takes the value t0 with probability 1- F(t0)> 0.
Characteristics of random variables. In probabilistic-statistical decision-making methods, a number of characteristics of random variables are used, expressed through distribution functions and probability density.
When describing income differentiation, when finding confidence limits for the parameters of distributions of random variables, and in many other cases, such a concept as “order quantile” is used. R", where 0< p < 1 (обозначается x p). Order quantile R is the value of a random variable for which the distribution function takes the value R or there is a "jump" from a value less than R up to a value greater R(Fig. 2). It may happen that this condition is satisfied for all values of x belonging to this interval (i.e., the distribution function is constant on this interval and is equal to R). Then each such value is called a "quantile of the order R».

Fig.2. Definition of a quantile x p order R.
For continuous distribution functions, as a rule, there is a single quantile x p order R(Fig. 2), and
F(x p) = p. (2)
Example 4 Let's find the quantile x p order R for the distribution function F(x) from (1).
At 0< p < 1 квантиль x p is found from the equation
those. x p = a + p(b – a) = a( 1- p)+bp. At p= 0 any x < a is the order quantile p= 0. Order quantile p= 1 is any number x > b.
For discrete distributions usually does not exist x p satisfying equation (2). More precisely, if the distribution of a random variable is given in Table 1, where x 1< x 2 < … < x k , then equality (2), considered as an equation with respect to x p, has solutions only for k values p, namely,
p \u003d p 1,
p \u003d p 1 + p 2,
p \u003d p 1 + p 2 + p 3,
p \u003d p 1 + p 2 + ... + p m, 3< m < k,
p \u003d p 1 + p 2 + ... + p k.
Table 1.
Distribution of a discrete random variable
|
Values x random variable X |
||||
|
Probabilities P(X=x) |
For the listed k probability values p solution x p equation (2) is not unique, namely,
F(x) = p 1 + p 2 + ... + p m
for all X such that x m< x < xm+1 . Those. x p - any number from the range (x m ; x m+1 ]. For everyone else R from the interval (0;1) not included in the list (3), there is a “jump” from a value less than R up to a value greater R. Namely, if
p 1 + p 2 + … + p m
then x p \u003d x m + 1.
The considered property of discrete distributions creates significant difficulties in tabulating and using such distributions, since it is impossible to accurately maintain the typical numerical values of the distribution characteristics. In particular, this is true for the critical values and significance levels of nonparametric statistical tests (see below), since the distributions of the statistics of these tests are discrete.
The order quantile is of great importance in statistics. R= S. It is called the median (random variable X or its distribution function F(x)) and denoted Me(X). In geometry, there is the concept of "median" - a straight line passing through the vertex of a triangle and dividing its opposite side in half. In mathematical statistics, the median bisects not the side of the triangle, but the distribution of a random variable: equality F(x0.5)= 0.5 means that the probability of getting to the left x0.5 and the probability of getting right x0.5(or directly to x0.5) are equal to each other and equal to S, i.e.
P(X < x 0,5) = P(X > x 0.5) = S.
The median indicates the "center" of the distribution. From the point of view of one of the modern concepts - the theory of stable statistical procedures - the median is a better characteristic of a random variable than the mathematical expectation. When processing measurement results in an ordinal scale (see the chapter on measurement theory), the median can be used, but the mathematical expectation cannot.
Such a characteristic of a random variable as a mode has a clear meaning - the value (or values) of a random variable corresponding to a local maximum of the probability density for a continuous random variable or a local maximum of the probability for a discrete random variable.
If a x0 is the mode of a random variable with density f(x), then, as is known from differential calculus, .
A random variable can have many modes. So, for uniform distribution (1) each point X such that a< x < b , is fashion. However, this is an exception. Most of the random variables used in probabilistic-statistical decision-making methods and other applied research have one mode. Random variables, densities, distributions that have one mode are called unimodal.
The mathematical expectation for discrete random variables with a finite number of values is considered in the chapter "Events and Probabilities". For a continuous random variable X expected value M(X) satisfies the equality

which is an analogue of formula (5) from statement 2 of the chapter "Events and probabilities".
Example 5 Mathematical expectation for a uniformly distributed random variable X equals
For the random variables considered in this chapter, all those properties of mathematical expectations and variances that were considered earlier for discrete random variables with a finite number of values are true. However, we do not provide proofs of these properties, since they require deepening into mathematical subtleties, which is not necessary for understanding and qualified application of probabilistic-statistical decision-making methods.
Comment. In this textbook, mathematical subtleties are deliberately avoided, connected, in particular, with the concepts of measurable sets and measurable functions, the -algebra of events, and so on. Those wishing to master these concepts should refer to the specialized literature, in particular, to the encyclopedia.
Each of the three characteristics - mathematical expectation, median, mode - describes the "center" of the probability distribution. The concept of "center" can be defined in different ways - hence the three different characteristics. However, for an important class of distributions - symmetric unimodal - all three characteristics coincide.
Distribution density f(x) is the density of the symmetric distribution, if there is a number x 0 such that
![]() . (3)
. (3)
Equality (3) means that the graph of the function y = f(x) symmetrical about a vertical line passing through the center of symmetry X = X 0 . From (3) it follows that the symmetric distribution function satisfies the relation
![]() (4)
(4)
For a symmetrical distribution with one mode, the mean, median, and mode are the same and equal x 0.
The most important case is symmetry with respect to 0, i.e. x 0= 0. Then (3) and (4) become equalities
![]() (6)
(6)
respectively. The above relations show that there is no need to tabulate symmetric distributions for all X, it suffices to have tables for x > x0.
We note one more property of symmetric distributions, which is constantly used in probabilistic-statistical decision-making methods and other applied research. For a continuous distribution function
P(|X| < a) = P(-a < X < a) = F(a) – F(-a),
where F is the distribution function of the random variable X. If the distribution function F is symmetric with respect to 0, i.e. formula (6) is valid for it, then
P(|X| < a) = 2F(a) – 1.
Another formulation of the statement under consideration is often used: if
![]() .
.
If and are quantiles of the order and, respectively (see (2)) of a distribution function symmetric with respect to 0, then it follows from (6) that
From the characteristics of the position - mathematical expectation, medians, modes - let's move on to the characteristics of the spread of a random variable X: variance , standard deviation and coefficient of variation v. The definition and properties of the variance for discrete random variables were considered in the previous chapter. For continuous random variables
The standard deviation is the non-negative value of the square root of the variance:
The coefficient of variation is the ratio of the standard deviation to the mathematical expectation:
The coefficient of variation is applied when M(X)> 0. It measures the spread in relative units, while the standard deviation is in absolute units.
Example 6 For a uniformly distributed random variable X find the variance, standard deviation and coefficient of variation. The dispersion is:

Variable substitution makes it possible to write:
where c = (b – a)/ 2. Therefore, the standard deviation is equal to and the coefficient of variation is:
For every random variable X determine three more quantities - centered Y, normalized V and given U. Centered random variable Y is the difference between the given random variable X and its mathematical expectation M(X), those. Y = X - M(X). Mathematical expectation of a centered random variable Y is equal to 0, and the variance is the variance of the given random variable: M(Y) = 0, D(Y) = D(X). distribution function FY(x) centered random variable Y related to the distribution function F(x) initial random variable X ratio:
FY(x) = F(x + M(X)).
For the densities of these random variables, the equality
fY(x) = f(x + M(X)).
Normalized random variable V is the ratio of this random variable X to its standard deviation , i.e. . Mathematical expectation and variance of a normalized random variable V expressed through characteristics X So:
![]() ,
,
where v is the coefficient of variation of the original random variable X. For the distribution function F V(x) and density f V(x) normalized random variable V we have:
where F(x) is the distribution function of the original random variable X, a f(x) is its probability density.
Reduced random variable U is a centered and normalized random variable:
![]() .
.
For a reduced random variable
Normalized, centered and reduced random variables are constantly used both in theoretical studies, and in algorithms, software products, normative-technical and instructive-methodical documentation. In particular, because the equalities ![]() make it possible to simplify the substantiation of methods, formulations of theorems, and calculation formulas.
make it possible to simplify the substantiation of methods, formulations of theorems, and calculation formulas.
Transformations of random variables and more are used general plan. So if Y = aX + b, where a and b are some numbers, then
Example 7 If then Y is the reduced random variable, and formulas (8) are transformed into formulas (7).
With every random variable X you can connect a lot of random variables Y given by the formula Y = aX + b at various a> 0 and b. This set is called scale-shift family, generated by a random variable X. Distribution functions FY(x) constitute a scale-shift family of distributions generated by the distribution function F(x). Instead of Y = aX + b frequently used notation
![]()
Number With is called the shift parameter, and the number d- scale parameter. Formula (9) shows that X- the result of measuring a certain quantity - goes into At- the result of the measurement of the same value, if the beginning of the measurement is moved to the point With, and then use the new unit of measure, in d times greater than the old one.
For the scale-shift family (9), the distribution X is called standard. In probabilistic-statistical decision-making methods and other applied research, the standard normal distribution, the standard Weibull-Gnedenko distribution, the standard gamma distribution, etc. are used (see below).
Other transformations of random variables are also used. For example, for a positive random variable X consider Y= log X, where lg X – decimal logarithm numbers X. Chain of equalities
F Y (x) = P( lg X< x) = P(X < 10x) = F( 10x)
relates distribution functions X and Y.
When processing data, such characteristics of a random variable are used X like moments of order q, i.e. mathematical expectations of a random variable X q, q= 1, 2, … Thus, the mathematical expectation itself is a moment of order 1. For a discrete random variable, the moment of order q can be calculated as
![]()
For a continuous random variable

Moments of order q also called the initial moments of the order q, in contrast to related characteristics - the central moments of the order q, given by the formula
Thus, dispersion is a central moment of order 2.
Normal distribution and the central limit theorem. In probabilistic-statistical decision-making methods, we often talk about a normal distribution. Sometimes they try to use it to model the distribution of the initial data (these attempts are not always justified - see below). More importantly, many data processing methods are based on the fact that the calculated values have distributions that are close to normal.
Let X 1 , X 2 ,…, X n M(X i) = m and dispersions D(X i) = , i= 1, 2,…, n,… As follows from the results of the previous chapter,
Consider the reduced random variable U n for the sum ![]() , namely,
, namely,
![]()
As follows from formulas (7), M(U n) = 0, D(U n) = 1.
(for identically distributed terms). Let X 1 , X 2 ,…, X n, … are independent identically distributed random variables with mathematical expectations M(X i) = m and dispersions D(X i) = , i= 1, 2,…, n,… Then for any x there is a limit

where F(x)– function of the standard normal distribution.
More about the function F(x) - below (it reads “fi from x”, because F- Greek capital letter "phi").
The Central Limit Theorem (CLT) takes its name from the fact that it is the central, most commonly used mathematical result probability theory and mathematical statistics. The history of the CLT takes about 200 years - from 1730, when the English mathematician A. De Moivre (1667-1754) published the first result related to the CLT (see below about the Moivre-Laplace theorem), until the twenties - thirties of the twentieth century, when Finn J.W. Lindeberg, Frenchman Paul Levy (1886-1971), Yugoslav V. Feller (1906-1970), Russian A.Ya. Khinchin (1894-1959) and other scientists obtained necessary and sufficient conditions for the validity of the classical central limit theorem.
The development of the subject under consideration did not stop there at all - they studied random variables that do not have dispersion, i.e. those for whom

(academician B.V. Gnedenko and others), the situation when random variables (more precisely, random elements) of a more complex nature than numbers are summed up (academicians Yu.V. Prokhorov, A.A. Borovkov and their associates), etc. .d.
distribution function F(x) is given by the equality
![]() ,
,
where is the density of the standard normal distribution, which has quite complex expression:
![]() .
.
Here \u003d 3.1415925 ... is a number known in geometry, equal to the ratio of the circumference to the diameter, e\u003d 2.718281828 ... - the base of natural logarithms (to remember this number, note that 1828 is the year of birth of the writer Leo Tolstoy). As is known from mathematical analysis,

When processing the results of observations, the normal distribution function is not calculated according to the above formulas, but is found using special tables or computer programs. The best in Russian “Tables of Mathematical Statistics” were compiled by Corresponding Members of the USSR Academy of Sciences L.N. Bolshev and N.V. Smirnov.
The form of the density of the standard normal distribution follows from the mathematical theory, which we cannot consider here, as well as the proof of the CLT.
For illustration, we present small tables of the distribution function F(x)(Table 2) and its quantiles (Table 3). Function F(x) is symmetrical with respect to 0, which is reflected in Tables 2-3.
Table 2.
Function of the standard normal distribution.
If the random variable X has a distribution function F(x), then M(X) = 0, D(X) = 1. This statement is proved in probability theory based on the form of the probability density . It agrees with a similar statement for the characteristics of the reduced random variable U n, which is quite natural, since the CLT states that with an infinite increase in the number of terms, the distribution function U n tends to the standard normal distribution function F(x), and for any X.
Table 3
Quantiles of the standard normal distribution.
|
Order quantile R |
Order quantile R |
||
Let us introduce the concept of a family of normal distributions. By definition, a normal distribution is the distribution of a random variable X, for which the distribution of the reduced random variable is F(x). As follows from common properties scale-shift families of distributions (see above), the normal distribution is the distribution of a random variable
where X is a random variable with distribution F(X), and m = M(Y), = D(Y). Normal distribution with shift parameters m and scale is usually denoted N(m, ) (sometimes the notation N(m, ) ).
As follows from (8), the probability density of the normal distribution N(m, ) there is

Normal distributions form a scale-shift family. In this case, the scale parameter is d= 1/ , and the shift parameter c = - m/ .
For the central moments of the third and fourth order of the normal distribution, the equalities are true
![]()
These equalities underlie the classical methods of checking that the results of observations follow a normal distribution. At present, normality is usually recommended to be checked by the criterion W Shapiro - Wilka. The normality check problem is discussed below.
If random variables X 1 and X 2 have distribution functions N(m 1
, 1
)
and N(m 2
, 2
)
respectively, then X 1+ X 2 has a distribution ![]() Therefore, if the random variables X 1
,
X 2
,…,
X n N(m, )
, then their arithmetic mean
Therefore, if the random variables X 1
,
X 2
,…,
X n N(m, )
, then their arithmetic mean
![]()
has a distribution N(m, ) . These properties of the normal distribution are constantly used in various probabilistic-statistical decision-making methods, in particular, in the statistical control of technological processes and in statistical acceptance control by a quantitative attribute.
The normal distribution defines three distributions that are now commonly used in statistical data processing.
Distribution (chi - square) - distribution of a random variable
where random variables X 1 , X 2 ,…, X n are independent and have the same distribution N(0.1). In this case, the number of terms, i.e. n, is called the "number of degrees of freedom" of the chi-square distribution.
Distribution t Student is the distribution of a random variable
where random variables U and X independent, U has a standard normal distribution N(0,1) and X– distribution chi – square with n degrees of freedom. Wherein n is called the "number of degrees of freedom" of the Student's distribution. This distribution was introduced in 1908 by the English statistician W. Gosset, who worked at a beer factory. Probabilistic-statistical methods were used to make economic and technical decisions at this factory, so its management forbade V. Gosset to publish scientific articles under his own name. In this way, a trade secret was protected, "know-how" in the form of probabilistic-statistical methods developed by W. Gosset. However, he was able to publish under the pseudonym "Student". The history of Gosset - Student shows that for another hundred years the great economic efficiency of probabilistic-statistical decision-making methods was obvious to British managers.
The Fisher distribution is the distribution of a random variable
where random variables X 1 and X 2 are independent and have chi distributions - the square with the number of degrees of freedom k 1 and k 2 respectively. At the same time, a couple (k 1 , k 2 ) is a pair of "numbers of degrees of freedom" of the Fisher distribution, namely, k 1 is the number of degrees of freedom of the numerator, and k 2 is the number of degrees of freedom of the denominator. The distribution of the random variable F is named after the great English statistician R. Fisher (1890-1962), who actively used it in his work.
Expressions for the distribution functions of chi - square, Student and Fisher, their densities and characteristics, as well as tables can be found in the special literature (see, for example,).
As already noted, normal distributions are currently often used in probabilistic models in various applied fields. Why is this two-parameter family of distributions so widespread? It is clarified by the following theorem.
Central limit theorem(for differently distributed terms). Let X 1 , X 2 ,…, X n,… are independent random variables with mathematical expectations M(X 1 ), M(X 2 ),…, M(X n), … and dispersions D(X 1 ), D(X 2 ),…, D(X n), … respectively. Let
Then, under the validity of certain conditions that ensure the smallness of the contribution of any of the terms to U n,
![]()
for anyone X.
The conditions in question will not be formulated here. They can be found in the specialized literature (see, for example,). "Clarifying the conditions under which the CPT operates is the merit of the outstanding Russian scientists A.A. Markov (1857-1922) and, in particular, A.M. Lyapunov (1857-1918)" .
The central limit theorem shows that in the case when the result of measurement (observation) is formed under the influence of many reasons, each of them making only a small contribution, and the cumulative result is determined by additively, i.e. by addition, then the distribution of the measurement (observation) result is close to normal.
It is sometimes believed that for the distribution to be normal it is sufficient that the result of the measurement (observation) X formed under the influence of many causes, each of which has a small effect. This is not true. What matters is how these causes work. If additive, then X has an approximately normal distribution. If a multiplicatively(that is, the actions of individual causes are multiplied, not added), then the distribution X not close to normal, but to the so-called. logarithmically normal, i.e. not X, and lg X has an approximately normal distribution. If there are no grounds to believe that one of these two mechanisms for the formation of the final result (or some other well-defined mechanism) is operating, then about the distribution X nothing definite can be said.
From what has been said, it follows that in a specific applied problem, the normality of the results of measurements (observations), as a rule, cannot be established from general considerations, it should be checked using statistical criteria. Or use non-parametric statistical methods that are not based on assumptions about the distribution functions of measurement results (observations) belonging to one or another parametric family.
Continuous distributions used in probabilistic-statistical decision-making methods. In addition to the scale-shift family of normal distributions, a number of other distribution families are widely used - logarithmically normal, exponential, Weibull-Gnedenko, gamma distributions. Let's take a look at these families.
Random value X has a log-normal distribution if the random variable Y= log X has a normal distribution. Then Z=ln X = 2,3026…Y also has a normal distribution N(a 1 ,σ 1), where ln X- natural logarithm X. The density of the log-normal distribution is:

It follows from the central limit theorem that the product X = X 1 X 2 … X n independent positive random variables X i, i = 1, 2,…, n, at large n can be approximated by a log-normal distribution. In particular, the multiplicative model of the formation wages or income leads to a recommendation to approximate the distributions of wages and incomes by log-normal laws. For Russia, this recommendation turned out to be justified - the statistics confirm it.
There are other probabilistic models that lead to the log-normal law. A classical example of such a model is given by A.N. ball mills have a log-normal distribution.
Let's move on to another family of distributions, widely used in various probabilistic-statistical decision-making methods and other applied research, the family of exponential distributions. Let's start with a probabilistic model that leads to such distributions. To do this, consider the "stream of events", i.e. a sequence of events occurring one after the other at some point in time. Examples are: call flow at the telephone exchange; the flow of equipment failures in the technological chain; flow of product failures during product testing; the flow of customer requests to the bank branch; the flow of buyers applying for goods and services, etc. In the theory of event flows, a theorem is valid that is similar to the central limit theorem, but in it we are talking not about the summation of random variables, but about the summation of the flows of events. We consider the total flow composed of a large number independent flows, none of which has a predominant effect on the total flow. For example, the flow of calls arriving at the telephone exchange is made up of a large number of independent call flows originating from individual subscribers. It is proved that in the case when the characteristics of the flows do not depend on time, the total flow is completely described by one number - the intensity of the flow. For the total flow, consider a random variable X- the length of the time interval between successive events. Its distribution function has the form
 (10)
(10)
This distribution is called the exponential distribution because formula (10) involves the exponential function e -λ x. The value 1/λ is a scale parameter. Sometimes a shift parameter is also introduced With, exponential is the distribution of a random variable X + c, where the distribution X is given by formula (10).
Exponential distributions are a special case of the so-called. Weibull - Gnedenko distributions. They are named after the engineer W. Weibull, who introduced these distributions into the practice of analyzing the results of fatigue tests, and the mathematician B.V. Gnedenko (1912-1995), who received such distributions as limiting ones when studying the maximum of the test results. Let X- a random variable that characterizes the duration of the operation of a product, complex system, element (i.e. resource, operating time to the limit state, etc.), the duration of the operation of an enterprise or the life of a living being, etc. Failure rate plays an important role
![]() (11)
(11)
where F(x) and f(x) - distribution function and density of a random variable X.
Let us describe the typical behavior of the failure rate. The entire time interval can be divided into three periods. On the first of them, the function λ(x) has high values and a clear tendency to decrease (most often it decreases monotonically). This can be explained by the presence in the batch under consideration of product units with obvious and latent defects, which lead to a relatively quick failure of these product units. The first period is called the "break-in" (or "break-in") period. This is usually covered by the warranty period.
Then comes the period of normal operation, characterized by an approximately constant and relatively low failure rate. The nature of failures during this period is of a sudden nature (accidents, errors of operating personnel, etc.) and does not depend on the duration of operation of a product unit.
Finally, the last period of operation is the period of aging and wear. The nature of failures during this period is in irreversible physical, mechanical and chemical changes materials, leading to a progressive deterioration in the quality of a unit of production and its final failure.
Each period has its own type of function λ(x). Consider the class of power dependencies
λ(х) = λ0bxb -1 , (12)
where λ 0 > 0 and b> 0 - some numeric parameters. Values b < 1, b= 0 and b> 1 correspond to the type of failure rate during the periods of running-in, normal operation and aging, respectively.
Relation (11) for a given failure rate λ(x)- differential equation with respect to the function F(x). From theory differential equations follows that
 (13)
(13)
Substituting (12) into (13), we get that
 (14)
(14)
The distribution given by formula (14) is called the Weibull - Gnedenko distribution. Because the
then it follows from formula (14) that the quantity a, given by formula (15), is a scaling parameter. Sometimes a shift parameter is also introduced, i.e. Weibull - Gnedenko distribution functions are called F(x - c), where F(x) is given by formula (14) for some λ 0 and b.
The density of the Weibull - Gnedenko distribution has the form
 (16)
(16)
where a> 0 - scale parameter, b> 0 - form parameter, With- shift parameter. In this case, the parameter a from formula (16) is related to the parameter λ 0 from formula (14) by the ratio indicated in formula (15).
The exponential distribution is a very special case of the Weibull - Gnedenko distribution, corresponding to the value of the shape parameter b = 1.
The Weibull - Gnedenko distribution is also used in the construction of probabilistic models of situations in which the behavior of an object is determined by the "weakest link". An analogy with a chain is implied, the safety of which is determined by that link that has the lowest strength. In other words, let X 1 , X 2 ,…, X n are independent identically distributed random variables,
X(1)=min( X 1 , X 2 ,…, X n), X(n)=max( X 1 , X 2 ,…, X n).
In a number of applied problems, an important role is played by X(1) and X(n) , in particular, when studying the maximum possible values ("records") of certain values, for example, insurance payments or losses due to commercial risks, when studying the limits of elasticity and endurance of steel, a number of reliability characteristics, etc. It is shown that for large n the distributions X(1) and X(n) , as a rule, are well described by Weibull - Gnedenko distributions. Foundational contributions to the study of distributions X(1) and X(n) introduced Soviet mathematician B.V. Gnedenko. The works of V. Weibull, E. Gumbel, V.B. Nevzorova, E.M. Kudlaev and many other specialists.
Let's move on to the family of gamma distributions. They are widely used in economics and management, theory and practice of reliability and testing, in various fields of technology, meteorology, etc. In particular, in many situations, the gamma distribution is subject to such quantities as the total service life of the product, the length of the chain of conductive dust particles, the time it takes the product to reach the limit state during corrosion, the operating time up to k th refusal, k= 1, 2, …, etc. The life expectancy of patients with chronic diseases, the time to achieve a certain effect in the treatment in some cases have a gamma distribution. This distribution is the most adequate for describing demand in economic and mathematical models of inventory management (logistics).
The density of the gamma distribution has the form
 (17)
(17)
The probability density in formula (17) is determined by three parameters a, b, c, where a>0, b>0. Wherein a is a form parameter, b- scale parameter and With- shift parameter. Factor 1/Γ(a) is a normalization, it is introduced in order to
![]()
Here Γ(а)- one of the special functions used in mathematics, the so-called "gamma function", by which the distribution given by formula (17) is also named,

At a fixed a formula (17) defines a scale-shift family of distributions generated by a distribution with density
 (18)
(18)
The distribution of the form (18) is called the standard gamma distribution. It is obtained from formula (17) with b= 1 and With= 0.
A special case of gamma distributions at a= 1 are exponential distributions (with λ = 1/b). With natural a and With=0 gamma distributions are called Erlang distributions. From the works of the Danish scientist K.A. Erlang (1878-1929), an employee of the Copenhagen telephone company, who studied in 1908-1922. the functioning of telephone networks, the development of the theory of queuing began. This theory is engaged in probabilistic-statistical modeling of systems in which the flow of requests is serviced in order to make optimal decisions. Erlang distributions are used in the same application areas as exponential distributions. This is based on the following mathematical fact: the sum of k independent random variables exponentially distributed with the same parameters λ and With, has a gamma distribution with shape parameter a =k, scale parameter b= 1/λ and the shift parameter kc. At With= 0 we get the Erlang distribution.
If the random variable X has a gamma distribution with shape parameter a such that d = 2 a- an integer, b= 1 and With= 0, then 2 X has a chi-squared distribution with d degrees of freedom.
A random variable X with a gvmma distribution has the following characteristics:
Expected value M(X) =ab + c,
dispersion D(X) = σ 2 = ab 2 ,
The coefficient of variation
asymmetry ![]()
Excess ![]()
The normal distribution is an extreme case of the gamma distribution. More precisely, let Z be a random variable having a standard gamma distribution, given by formula(eighteen). Then
![]()
for anyone real number X, where F(x)- standard normal distribution function N(0,1).
In applied research, other parametric families of distributions are also used, of which the Pearson curve system, Edgeworth and Charlier series are the most well-known. They are not considered here.
Discrete distributions used in probabilistic-statistical decision-making methods. Most often, three families of discrete distributions are used - binomial, hypergeometric and Poisson, as well as some other families - geometric, negative binomial, multinomial, negative hypergeometric, etc.
As already mentioned, the binomial distribution takes place in independent trials, in each of which with a probability R event appears BUT. If a total number tests n given, then the number of trials Y, in which the event appeared BUT, has a binomial distribution. For a binomial distribution, the probability of being accepted as a random variable Y values y is determined by the formula
![]()
Number of combinations from n elements by y known from combinatorics. For all y, except for 0, 1, 2, …, n, we have P(Y= y)= 0. Binomial distribution with a fixed sample size n is set by the parameter p, i.e. binomial distributions form a one-parameter family. They are used in the analysis of sample research data, in particular, in the study of consumer preferences, selective control of product quality according to single-stage control plans, when testing populations of individuals in demography, sociology, medicine, biology, etc.
If a Y 1 and Y 2 - independent binomial random variables with the same parameter p 0 determined by samples with volumes n 1 and n 2 respectively, then Y 1 + Y 2 - binomial random variable with distribution (19) with R = p 0 and n= n 1 + n 2 . This remark expands the applicability of the binomial distribution, allowing you to combine the results of several groups of tests, when there is reason to believe that the same parameter corresponds to all these groups.
The characteristics of the binomial distribution were calculated earlier:
M(Y) = np, D(Y) = np( 1- p).
In the section "Events and probabilities" for a binomial random variable, the law big numbers:
![]()
for anyone . With the help of the central limit theorem, the law of large numbers can be refined by indicating how Y/ n differs from R.
De Moivre-Laplace theorem. For any numbers a and b, a< b, we have

where F(X) is a standard normal distribution function with mean 0 and variance 1.
To prove it, it suffices to use the representation Y as a sum of independent random variables corresponding to the outcomes of individual trials, formulas for M(Y) and D(Y) and the central limit theorem.
This theorem is for the case R= S was proved by the English mathematician A. Moivre (1667-1754) in 1730. In the above formulation, it was proved in 1810 by the French mathematician Pierre Simon Laplace (1749-1827).
Hypergeometric distribution takes place during selective control of a finite set of objects of volume N according to an alternative attribute. Each controlled object is classified either as having the attribute BUT, or as not possessing this feature. The hypergeometric distribution has a random variable Y, equal to the number objects that have an attribute BUT in a random sample of volume n, where n< N. For example, number Y defective units of products in a random sample of volume n from batch volume N has a hypergeometric distribution if n< N. Another example is the lottery. Let the sign BUT a ticket is a sign of “being winning”. Let all the tickets N, and some person has acquired n of them. Then the number of winning tickets for this person has a hypergeometric distribution.
For a hypergeometric distribution, the probability that a random variable Y takes the value y has the form
 (20)
(20)
where D is the number of objects that have the attribute BUT, in the considered set of volume N. Wherein y takes values from max(0, n - (N - D)) to min( n, D), with other y the probability in formula (20) is equal to 0. Thus, the hypergeometric distribution is determined by three parameters - the volume of the general population N, number of objects D in it, possessing the considered feature BUT, and sample size n.
Simple random sampling n from the total volume N is called a sample obtained as a result of random selection, in which any of the sets from n objects has the same probability of being selected. Methods for random selection of samples of respondents (interviewees) or units of piece products are considered in the instructive-methodical and normative-technical documents. One of the selection methods is as follows: objects are selected one from the other, and at each step each of the remaining objects in the set has the same chance of being selected. In the literature, for the type of samples under consideration, the terms “random sample”, “random sample without replacement” are also used.
Since the volumes of the general population (lots) N and samples n are commonly known, then the hypergeometric distribution parameter to be estimated is D. In statistical methods of product quality management D- usually the number of defective units in the batch. Of interest is also the characteristic of the distribution D/ N- defect level.
For hypergeometric distribution
The last factor in the variance expression is close to 1 if N>10 n. If, at the same time, we make the substitution p = D/ N, then the expressions for the mathematical expectation and variance of the hypergeometric distribution will turn into expressions for the mathematical expectation and variance of the binomial distribution. This is no coincidence. It can be shown that

at N>10 n, where p = D/ N. The limiting ratio is valid
and this limiting relation can be used for N>10 n.
The third widely used discrete distribution is the Poisson distribution. A random variable Y has a Poisson distribution if
 ,
,
where λ is the Poisson distribution parameter, and P(Y= y)= 0 for all others y(for y=0, 0!=1 is denoted). For the Poisson distribution
M(Y) = λ, D(Y) = λ.
This distribution is named after the French mathematician C.D. Poisson (1781-1840), who first derived it in 1837. The Poisson distribution is an extreme case of the binomial distribution, where the probability R implementation of the event is small, but the number of trials n great, and np= λ. More precisely, the limit relation
Therefore, the Poisson distribution (in the old terminology "distribution law") is often also called the "law of rare events".
The Poisson distribution arises in the theory of event flows (see above). It is proved that for the simplest flow with constant intensity Λ, the number of events (calls) that occurred during the time t, has a Poisson distribution with parameter λ = Λ t. Therefore, the probability that in time t no event will occur e - Λ t, i.e. the distribution function of the length of the interval between events is exponential.
The Poisson distribution is used in the analysis of the results of selective marketing surveys of consumers, the calculation of the operational characteristics of statistical acceptance control plans in the case of small values of the acceptance level of defectiveness, to describe the number of breakdowns of a statistically controlled technological process per unit of time, the number of "requirements for service" arriving per unit of time in queuing system, statistical patterns of accidents and rare diseases, etc.
Description of other parametric families of discrete distributions and their possibilities practical use considered in the literature.
In some cases, for example, when studying prices, output volumes or total time between failures in reliability problems, the distribution functions are constant on certain intervals in which the values of the random variables under study cannot fall.
| Previous |
Examples of solving problems on the topic "Random variables".
A task 1 . There are 100 tickets issued in the lottery. One win of 50 USD was played. and ten wins of $10 each. Find the law of distribution of the value X - the cost of a possible gain.
Solution. Possible values of X: x 1 = 0; x 2 = 10 and x 3 = 50. Since there are 89 “empty” tickets, then p 1 = 0.89, the probability of winning is 10 c.u. (10 tickets) – p 2 = 0.10 and for a win of 50 c.u. –p 3 = 0.01. In this way:
|
0,89 |
0,10 |
0,01 |
Easy to control: .
A task 2. The probability that the buyer has familiarized himself with the advertisement of the product in advance is 0.6 (p = 0.6). Selective quality control of advertising is carried out by polling buyers before the first one who has studied the advertisement in advance. Make a series of distribution of the number of interviewed buyers.
Solution. According to the condition of the problem p = 0.6. From: q=1 -p = 0.4. Substituting these values, we get: and construct a distribution series:
|
pi |
0,24 |
A task 3. A computer consists of three independently operating elements: a system unit, a monitor, and a keyboard. With a single sharp increase in voltage, the probability of failure of each element is 0.1. Based on the Bernoulli distribution, draw up the distribution law for the number of failed elements during a power surge in the network.
Solution. Consider Bernoulli distribution(or binomial): the probability that in n tests, event A will appear exactly k once: ![]() , or:
, or:
|
q n |
p n |
AT let's get back to the task.
Possible values of X (number of failures):
x 0 =0 - none of the elements failed;
x 1 =1 - failure of one element;
x 2 =2 - failure of two elements;
x 3 =3 - failure of all elements.
Since, by condition, p = 0.1, then q = 1 – p = 0.9. Using the Bernoulli formula, we get
, ,
, .
Control: .
Therefore, the desired distribution law:
|
0,729 |
0,243 |
0,027 |
0,001 |
Task 4. Produced 5000 rounds. The probability that one cartridge is defective ![]() . What is the probability that there will be exactly 3 defective cartridges in the entire batch?
. What is the probability that there will be exactly 3 defective cartridges in the entire batch?
Solution. Applicable Poisson distribution: this distribution is used to determine the probability that, given a very large
number of trials (mass trials), in each of which the probability of event A is very small, event A will occur k times: 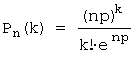 , where .
, where .
Here n \u003d 5000, p \u003d 0.0002, k \u003d 3. We find , then the desired probability:  .
.
Task 5. When firing before the first hit with the probability of hitting p = 0.6 for a shot, you need to find the probability that the hit will occur on the third shot.
Solution. Let us apply the geometric distribution: let independent trials be performed, in each of which the event A has a probability of occurrence p (and non-occurrence q = 1 - p). Trials end as soon as event A occurs.
Under such conditions, the probability that event A will occur on the kth test is determined by the formula: . Here p = 0.6; q \u003d 1 - 0.6 \u003d 0.4; k \u003d 3. Therefore, .
Task 6. Let the law of distribution of a random variable X be given:
Find the mathematical expectation.
Solution. .
Note that the probabilistic meaning of the mathematical expectation is the average value of a random variable.
Task 7. Find the variance of a random variable X with the following distribution law:
Solution. Here .
The law of distribution of the square of X 2 :
|
X 2 |
|||
Required variance: .
Dispersion characterizes the degree of deviation (scattering) of a random variable from its mathematical expectation.
Task 8. Let the random variable be given by the distribution:
|
10m |
|||
Find its numerical characteristics.
Solution: m, m 2 ,
M 2 , m.
About a random variable X, one can say either - its mathematical expectation is 6.4 m with a variance of 13.04 m 2 , or - its mathematical expectation is 6.4 m with a deviation of m. The second formulation is obviously clearer.
A task 9.
Random value X given by the distribution function:  .
.
Find the probability that, as a result of the test, the value X will take on a value contained in the interval ![]() .
.
Solution. The probability that X will take a value from a given interval is equal to the increment of the integral function in this interval, i.e. . In our case and , therefore
![]() .
.
A task 10. Discrete random variable X given by the distribution law:
Find distribution function F(x ) and build its graph.
Solution. Since the distribution function
![]() for
for ![]() , then
, then
at ;
at ;
at ;
at ;
Relevant chart:

Task 11. Continuous random variable X given by the differential distribution function:  .
.
Find the probability of hitting X to interval
Solution. Note that this is a special case of the exponential distribution law.
Let's use the formula: 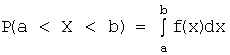 .
.
A task 12. Find the numerical characteristics of a discrete random variable X given by the distribution law:
|
–5 |
|||||||||
|
X 2 :
|
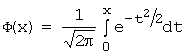 is the Laplace function.
is the Laplace function.Random variable A quantity is called that, as a result of tests carried out under the same conditions, takes on different, generally speaking, values, depending on random factors that are not taken into account. Examples of random variables: the number of points dropped on a dice, the number of defective items in a batch, the deviation of the point of impact of the projectile from the target, the uptime of the device, etc. Distinguish between discrete and continuous random variables. Discrete A random variable is called, the possible values of which form a countable set, finite or infinite (i.e., a set whose elements can be numbered).
continuous A random variable is called, the possible values of which continuously fill some finite or infinite interval of the numerical axis. The number of values of a continuous random variable is always infinite.
Random variables will be denoted capital letters the end of the Latin alphabet: X, Y, ...; values of a random variable - lower case: X, y... . In this way, X Denotes the entire set of possible values of a random variable, and X - Some specific meaning.
distribution law A discrete random variable is a correspondence given in any form between the possible values of a random variable and their probabilities.
Let the possible values of the random variable X Are . As a result of the test, the random variable will take one of these values, i.e. One event from a complete group of pairwise incompatible events will occur.
Let also the probabilities of these events be known:
Distribution law of a random variable X It can be written in the form of a table called Near distribution Discrete random variable:
The distribution series is equal (normalization condition).
Example 3.1. Find the distribution law of a discrete random variable X - the number of occurrences of the "eagle" in two coin tosses.
The distribution function is a universal form of setting the distribution law for both discrete and continuous random variables.
The distribution function of a random variableX The function is called F(X), Defined on the whole number line as follows:
F(X)= P(X< х ),
i.e. F(X) there is a probability that the random variable X Takes on a value less than X.
The distribution function can be represented graphically. For a discrete random variable, the graph has a stepped form. Let's build, for example, a graph of the distribution function of a random variable given by the following series (Fig. 3.1):
|
|
|


Rice. 3.1. Graph of the distribution function of a discrete random variable
Jumps of the function occur at points corresponding to the possible values of the random variable, and are equal to the probabilities of these values. At break points, the function F(X) is continuous on the left.
The plot of the distribution function of a continuous random variable is a continuous curve.
|
|
 X
XRice. 3.2. Graph of the distribution function of a continuous random variable
The distribution function has the following obvious properties:
1) ![]() , 2) , 3) ,
, 2) , 3) ,
4) ![]() at .
at .
We will call an event consisting in the fact that a random variable X Takes on a value X, Belonging to some semi-closed interval A£ X< B, By hitting a random variable on the interval [ A, B).
Theorem 3.1. The probability of a random variable falling into the interval [ A, B) is equal to the increment of the distribution function on this interval:
If we decrease the interval [ A, B), Assuming that , then in the limit, formula (3.1) instead of the probability of hitting the interval gives the probability of hitting the point, i.e., the probability that the random variable takes on the value A:
If the distribution function has a discontinuity at the point A, Then the limit (3.2) is equal to the jump value of the function F(X) at the point X=A, That is, the probabilities that the random variable will take on the value A (Fig. 3.3, BUT). If the random variable is continuous, i.e., the function is continuous F(X), then the limit (3.2) is equal to zero (Fig. 3.3, B)
Thus, the probability of any particular value of a continuous random variable is zero. However, this does not mean that the event is impossible. X=A, It only says that the relative frequency of this event will tend to zero with an unlimited increase in the number of tests.
|
BUT) |
 B)
B)Rice. 3.3. Distribution function jump
For continuous random variables, along with the distribution function, another form of specifying the distribution law is used - the distribution density.
If is the probability of hitting the interval , then the ratio characterizes the density with which the probability is distributed in the vicinity of the point X. The limit of this relation at , i.e. e. derivative, is called Distribution density(density of probability distribution, probability density) of a random variable X. We agree to denote the distribution density
 .
.
Thus, the distribution density characterizes the probability that a random variable will fall into the vicinity of the point X.
The plot of the distribution density is called crooked racesDefinitions(Figure 3.4).

Rice. 3.4. Distribution density type
Based on the definition and properties of the distribution function F(X), it is easy to establish the following properties of the distribution density F(X):
1) F(X)³0
2) 
3) 
4) 
For a continuous random variable, due to the fact that the probability of hitting a point is zero, the following equalities hold:
Example 3.2. Random value X Specified by the distribution density

Required:
A) find the value of the coefficient BUT;
B) find the distribution function;
C) find the probability of a random variable falling into the interval (0, ).
The distribution function or distribution density completely describes a random variable. Often, however, when solving practical problems, there is no need for complete knowledge of the law of distribution, it is enough to know only some of it. character traits. To do this, in the theory of probability, numerical characteristics of a random variable are used, expressing various properties of the distribution law. The main numerical characteristics are MathematicalExpectation, variance and standard deviation.
Expected value Characterizes the position of a random variable on the number axis. This is some average value of a random variable around which all its possible values are grouped.
Mathematical expectation of a random variable X Symbolized M(X) or T. The mathematical expectation of a discrete random variable is the sum of paired products of all possible values of the random variable and the probabilities of these values:

The mathematical expectation of a continuous random variable is determined using an improper integral:

Based on the definitions, it is easy to verify the validity the following properties mathematical expectation:
1. (mathematical expectation of a non-random variable FROM Equal to the most non-random value).
2. If ³0, then ³0.
4. If and independent, then .
Example 3.3. Find the mathematical expectation of a discrete random variable given by a series of distributions:
Solution.
 =0×0.2 + 1×0.4 + 2×0.3 + 3×0.1=1.3.
=0×0.2 + 1×0.4 + 2×0.3 + 3×0.1=1.3.
Example 3.4. Find the mathematical expectation of a random variable given by the distribution density:
 .
.
Solution.
Dispersion and standard deviation They are characteristics of the dispersion of a random variable, they characterize the spread of its possible values relative to the mathematical expectation.
dispersion D(X) random variable X The mathematical expectation of the squared deviation of a random variable from its mathematical expectation is called. For a discrete random variable, the variance is expressed by the sum:
![]() (3.3)
(3.3)
And for continuous - integral
 (3.4)
(3.4)
The variance has the dimension of the square of a random variable. scattering characteristic, Matching in sizeStee with random variable, is the standard deviation.
Dispersion properties:
1) are constant. In particular,
3) 
In particular,
Note that the calculation of the variance by formula (3.5) often turns out to be more convenient than by formula (3.3) or (3.4).
The value is called covariance random variables.
If a ![]() , then the value
, then the value

called Correlation coefficient random variables.
It can be shown that if ![]() , then the quantities are linearly dependent: where
, then the quantities are linearly dependent: where ![]()
Note that if they are independent, then
Example 3.5. Find the variance of a random variable given by the distribution series from Example 1.
Solution. To calculate the variance, you need to know the mathematical expectation. For a given random variable above, it was found: M=1.3. We calculate the variance using the formula (3.5):

Example 3.6. The random variable is given by the distribution density

Find the variance and standard deviation.
Solution. We first find the mathematical expectation:

(as an integral of odd function along a symmetrical interval).
Now we calculate the variance and standard deviation:

1. Binomial distribution. The random variable , equal to the number of "SUCCESSES" in the Bernoulli scheme, has a binomial distribution: ![]() ,
, ![]() .
.
The mathematical expectation of a random variable distributed according to the binomial law is
 .
.
The variance of this distribution is .
2. Poisson distribution  ,
,
Mathematical expectation and variance of a random variable with Poisson distribution , .
The Poisson distribution is often used when we are dealing with the number of events that occur in a span of time or space, such as the number of cars arriving at a car wash in an hour, the number of machine stops per week, the number of traffic accidents, etc.
The random variable has Geometric distribution with parameter if takes values with probabilities ![]() . A random variable with such a distribution makes sense Numbers of the first successful test in the Bernoulli scheme with the probability of success . The distribution table looks like:
. A random variable with such a distribution makes sense Numbers of the first successful test in the Bernoulli scheme with the probability of success . The distribution table looks like:

3. Normal distribution. The normal law of probability distribution occupies a special place among other distribution laws. In probability theory, it is proved that the probability density of the sum of independent or Weakly dependent, uniformly small (i.e., playing approximately the same role) terms with an unlimited increase in their number approaches the normal distribution law as close as desired, regardless of what distribution laws these terms have (the central limit theorem of A. M. Lyapunov).
Let us check whether the requirement of uniform boundedness of the variance is satisfied. Let's write the distribution law  :
:
|
|
|
|
|
|
|





Let's find the mathematical expectation  :
:
Let's find the variance  :
:
This function is increasing, so to calculate the variance limiting constant, you can calculate the limit:

Thus, the variances of the given random variables are unbounded, which was to be proved.
B) It follows from the formulation of Chebyshev's theorem that the requirement of uniform boundedness of variances is a sufficient, but not a necessary condition, therefore it cannot be argued that this theorem cannot be applied to a given sequence.
The sequence of independent random variables Х 1 , Х 2 , …, Х n , … is given by the distribution law
![]()
D(X n)=M(X n 2)- 2 ,
keep in mind that M(X n)=0, we will find (calculations are left to the reader)
![]()
Let's temporarily assume that n changes continuously (to emphasize this assumption, we denote n by x), and examine the function φ(x)=x 2 /2 x-1 for an extremum.
Equating the first derivative of this function to zero, we find the critical points x 1 \u003d 0 and x 2 \u003d ln 2.
We discard the first point as not of interest (n does not take on a value equal to zero); it is easy to see that at the points x 2 =2/ln 2 the function φ(x) has a maximum. Considering that 2/ln 2 ≈ 2.9 and that N is a positive integer, we calculate the variance D(X n)= (n 2 /2 n -1)α 2 for integers closest to 2.9 (left and right), t .e. for n=2 and n=3.
At n=2, the dispersion D(X 2)=2α 2 , at n=3, the dispersion D(X 3)=9/4α 2 . Obviously,
(9/4)α 2 > 2α 2 .
Thus, the largest possible variance is equal to (9/4)α 2 , i.e. variances of random variables Хn are uniformly limited by the number (9/4)α 2 .
The sequence of independent random variables X 1 , X 2 , …, X n , … is given by the distribution law
![]()
Is Chebyshev's theorem applicable to a given sequence?
Comment. Since the random variables X are equally distributed and independent, the reader familiar with Khinchin's theorem can confine himself to calculating only the mathematical expectation and make sure that it is over.
Since the random variables X n are independent, they are even more and pairwise independent, i.e. the first requirement of Chebyshev's theorem is satisfied.
It is easy to find that M(X n)=0, i.e. the first requirement of the finiteness of mathematical expectations is satisfied.
It remains to verify the feasibility of the requirement of uniform boundedness of variances. According to the formula
D(X n)=M(X n 2)- 2 ,
keep in mind that M(X n)=0, we find
Thus, the largest possible variance is 2, i.e. dispersions of random variables Х n are uniformly limited by the number 2.
So, all the requirements of the Chebyshev theorem are satisfied, therefore, this theorem is applicable to the sequence under consideration.

Find the probability that, as a result of the test, the value X will take on a value contained in the interval (0, 1/3).
Random variable Х is given on the whole axis Оx by the function distributed F(x)=1/2+(arctg x)/π. Find the probability that, as a result of the test, the value X will take on a value contained in the interval (0, 1). The probability that X will take the value contained in the interval (a, b) is equal to the increment of the distribution function on this interval: P(a P(0<
Х <1) = F(1)-F(0)
= x =1 -
x =0
= 1/4 Random variable X distribution function Find the probability that, as a result of the test, the value X will take on a value contained in the interval (-1, 1). The probability that X will take the value contained in the interval (a, b) is equal to the increment of the distribution function on this interval: P(a P(-1<
Х <1) = F(1)-F(-1)
= x =-1
– x =1
= 1/3. The distribution function of a continuous random variable X (uptime of some device) is equal to F(x)=1-e -x/ T (x≥0). Find the probability of failure-free operation of the device for the time x≥T. The probability that X will take the value contained in the interval x≥T is equal to the increment of the distribution function on this interval: P(0 P(x≥T) = 1 - P(T The random variable X is given by the distribution function Find the probability that, as a result of the test, X will take on a value: a) less than 0.2; b) less than three; c) at least three; d) at least five. a) Since for x≤2 the function F(x)=0, then F(0, 2)=0, i.e. P(x< 0, 2)=0; b) P(X< 3) = F(3) = x =3
= 1.5-1 = 0.5; c) events Х≥3 and Х<3 противоположны,
поэтому Р(Х≥3)+Р(Х<3)=1. Отсюда, учитывая,
что Р(Х<3)=0.5 [см. п. б.], получим Р(Х≥3) =
1-0.5 = 0.5; d) the sum of the probabilities of opposite events is equal to one, therefore P(X≥5) + P(X<5)=1. Отсюда, используя условие,
в силу которого при х>4 function F(x)=1, we get P(X≥5) = 1-P(X<5) = 1-F(5)
= 1-1 = 0. The random variable X is given by the distribution function Find the probability that, as a result of four independent trials, the value of X will exactly three times take a value belonging to the interval (0.25, 0.75). The probability that X will take the value contained in the interval (a, b) is equal to the increment of the distribution function on this interval: P(a P(0.25< X <0.75) =
F(0.75)-F(0.25) =
0.5 Therefore, or The random variable X is given on the entire Ox axis by the distribution function . Find a possible value that satisfies the condition: with a probability of random X as a result of the test will take on a value greater than Solution. Events and are opposite, therefore . Consequently, . Since , then . By definition of the distribution function, . Therefore, or Discrete random variable X is given by the distribution law So, the desired distribution function has the form Discrete random variable X is given by the distribution law Find the distribution function and draw its graph. Given the distribution function of a continuous random variable X Find the distribution density f(x). The distribution density is equal to the first derivative of the distribution function: A continuous random variable X is given by the distribution density in the interval ; outside this interval. Find the probability that X takes a value that belongs to the interval . Let's use the formula. By condition and . Therefore, the desired probability A continuous random variable X is given by the distribution density Let's use the formula. By condition and The distribution density of a continuous random variable X in the interval (-π/2, π/2) is equal to f(x)=(2/π)*cos2x ; outside this interval f(x)=0. Find the probability that in three independent trials X takes exactly two times the value contained in the interval (0, π/4). We use the formula Р(a P(0 Answer: π+24π. fx=0, at x≤0cosx, at 0 We use the formula If x ≤0, then f(x)=0, therefore, F(x)=-∞00dx=0. If 0 F(x)=-∞00dx+0xcosxdx=sinx. If x≥ π2 , then F(x)=-∞00dx+0π2cosxdx+π2x0dx=sinx|0π2=1. So, the desired distribution function Fx=0, at x≤0sinx, at 0 The distribution density of a continuous random variable X is given: Fx=0, at x≤0sinx, at 0 Find the distribution function F(x). We use the formula The distribution density of a continuous random variable X is given on the entire Oh axis by the equation . Find the constant parameter C. In this way, The distribution density of a continuous random variable is given on the entire axis by the equality Find the constant parameter C. Solution. The distribution density must satisfy the condition . We require that this condition be satisfied for the given function: Let us first find the indefinite integral: Then we calculate the improper integral: In this way, Substituting (**) into (*), we finally get . The distribution density of a continuous random variable X in the interval is ; outside this interval f(x) = 0. Find the constant parameter C. Let us first find the indefinite integral: Then we calculate the improper integral: Substituting (**) into (*), we finally get . The distribution density of a continuous random variable X is given in the interval by the equality ; outside this interval f(x) = 0. Find the constant parameter C. Solution. The distribution density must satisfy the condition , but since f(x) outside the interval is equal to 0, it is enough that it satisfies: Let us first find the indefinite integral: Then we calculate the improper integral: Substituting (**) into (*), we finally get . The random variable X is given by the distribution density ƒ(x) = 2x in the interval (0,1); outside this interval ƒ(x) = 0. Find the mathematical expectation of X. R Substituting a = 0, b = 1, ƒ(x) = 2x, we get Answer: 2/3. The random variable X is given by the distribution density ƒ(x) = (1/2)x in the interval (0;2); outside this interval ƒ(x) = 0. Find the mathematical expectation of X. R Substituting a = 0, b = 2, ƒ(x) = (1/2)x, we get M(X) = Answer: 4/3. The random variable X in the interval (–s, s) is given by the distribution density ƒ R Substituting a = –с, b = c, ƒ(x) = , we get Considering that the integrand is odd and the limits of integration are symmetric with respect to the origin, we conclude that the integral is equal to zero. Therefore, M(X) = 0. This result can be obtained immediately if we take into account that the distribution curve is symmetrical about the straight line x = 0. The random variable X in the interval (2, 4) is given by the distribution density f(x)= The random variable X in the interval (3, 5) is given by the distribution density f(x)= Solution. We represent the distribution density in the form The random variable X in the interval (-1, 1) is given by the distribution density In probability theory, one has to deal with random variables, all of whose values cannot be sorted out. For example, it is impossible to take and "sort through" all the values of the random variable $X$ - the service time of the clock, since time can be measured in hours, minutes, seconds, milliseconds, etc. You can only specify a certain interval within which the values of a random variable are located. Continuous random variable is a random variable whose values completely fill a certain interval. Since it is not possible to sort through all the values of a continuous random variable, it can be specified using the distribution function. distribution function random variable $X$ is a function $F\left(x\right)$, which determines the probability that the random variable $X$ takes a value less than some fixed value $x$, i.e. $F\left(x\right)$ )=P\left(X< x\right)$. Distribution function properties: 1
. $0\le F\left(x\right)\le 1$. 2
. The probability that the random variable $X$ takes values from the interval $\left(\alpha ;\ \beta \right)$ is equal to the difference between the values of the distribution function at the ends of this interval: $P\left(\alpha< X < \beta \right)=F\left(\beta \right)-F\left(\alpha \right)$. 3
. $F\left(x\right)$ - non-decreasing. 4
. $(\mathop(lim)_(x\to -\infty ) F\left(x\right)=0\ ),\ (\mathop(lim)_(x\to +\infty ) F\left(x \right)=1\ )$. Example 1
$$P\left(0,3< X < 0,7\right)=F\left(0,7\right)-F\left(0,3\right)=0,7-0,3=0,4.$$ The function $f\left(x\right)=(F)"(x)$ is called the probability distribution density, that is, it is the first order derivative taken from the distribution function $F\left(x\right)$ itself. Properties of the function $f\left(x\right)$. 1
. $f\left(x\right)\ge 0$. 2
. $\int^x_(-\infty )(f\left(t\right)dt)=F\left(x\right)$. 3
. The probability that a random variable $X$ takes values from the interval $\left(\alpha ;\ \beta \right)$ is $P\left(\alpha< X < \beta \right)=\int^{\beta }_{\alpha }{f\left(x\right)dx}$. Геометрически это означает, что вероятность попадания случайной величины $X$ в интервал $\left(\alpha ;\ \beta \right)$ равна площади криволинейной трапеции, которая будет ограничена графиком функции $f\left(x\right)$, прямыми $x=\alpha ,\ x=\beta $ и осью $Ox$. 4
. $\int^(+\infty )_(-\infty )(f\left(x\right))=1$. Example 2
. A continuous random variable $X$ is given by the following distribution function $F(x)=\left\(\begin(matrix) The mathematical expectation of a continuous random variable $X$ is calculated by the formula $$M\left(X\right)=\int^(+\infty )_(-\infty )(xf\left(x\right)dx).$$ Example 3
. Find $M\left(X\right)$ for the random variable $X$ from example $2$. $$M\left(X\right)=\int^(+\infty )_(-\infty )(xf\left(x\right)\ dx)=\int^1_0(x\ dx)=(( x^2)\over (2))\bigg|_0^1=((1)\over (2)).$$ The variance of a continuous random variable $X$ is calculated by the formula $$D\left(X\right)=\int^(+\infty )_(-\infty )(x^2f\left(x\right)\ dx)-(\left)^2.$$ Example 4
. Let's find $D\left(X\right)$ for the random variable $X$ from example $2$. $$D\left(X\right)=\int^(+\infty )_(-\infty )(x^2f\left(x\right)\ dx)-(\left)^2=\int^ 1_0(x^2\ dx)-(\left(((1)\over (2))\right))^2=((x^3)\over (3))\bigg|_0^1-( (1)\over (4))=((1)\over (3))-((1)\over (4))=((1)\over(12)).$$


![]() From here, or.
From here, or.![]() . From here, or.
. From here, or.![]()

![]()





 For x=0 the derivative does not exist.
For x=0 the derivative does not exist.![]() in the interval ; outside this interval. Find the probability that X takes a value that belongs to the interval .
in the interval ; outside this interval. Find the probability that X takes a value that belongs to the interval .![]() . Therefore, the desired probability
. Therefore, the desired probability![]() .
. . (*)
. (*)![]() .
.![]() .
. . (*)
. (*)![]() .
.![]()
![]() .
. . (*)
. (*)![]() (**)
(**)![]() We require that this condition be satisfied for the given function:
We require that this condition be satisfied for the given function:![]() .
. . (*)
. (*)![]() (**)
(**) solution. We use the formula
solution. We use the formula
 solution. We use the formula
solution. We use the formula =
4/3
=
4/3 (x) = ; outside this interval ƒ(x) = 0. Find the mathematical expectation of X.
(x) = ; outside this interval ƒ(x) = 0. Find the mathematical expectation of X. solution. We use the formula
solution. We use the formula

![]()
![]() . From this it can be seen that at x=3 the distribution density reaches a maximum; Consequently, . The distribution curve is symmetrical with respect to the straight line x=3, therefore and .
. From this it can be seen that at x=3 the distribution density reaches a maximum; Consequently, . The distribution curve is symmetrical with respect to the straight line x=3, therefore and .![]() ; outside this interval f(x)=0. Find the mode, mean, and median of X.
; outside this interval f(x)=0. Find the mode, mean, and median of X.![]() . From this it can be seen that at x=3 the distribution density reaches a maximum; Consequently, . The distribution curve is symmetrical with respect to the straight line x=4, therefore and .
. From this it can be seen that at x=3 the distribution density reaches a maximum; Consequently, . The distribution curve is symmetrical with respect to the straight line x=4, therefore and .![]() ; outside this interval f(x)=0. Find: a) fashion; b) the median X.
; outside this interval f(x)=0. Find: a) fashion; b) the median X.
Distribution function of a continuous random variable
0,\ x\le 0\\
x,\0< x\le 1\\
1,\x>1
\end(matrix)\right.$. The probability that a random variable $X$ falls into the interval $\left(0.3;0.7\right)$ can be found as the difference between the values of the distribution function $F\left(x\right)$ at the ends of this interval, i.e.:Probability density
0,\ x\le 0\\
x,\0< x\le 1\\
1,\x>1
\end(matrix)\right.$. Then the density function $f\left(x\right)=(F)"(x)=\left\(\begin(matrix)
0,\ x\le 0 \\
1,\ 0 < x\le 1\\
0,\x>1
\end(matrix)\right.$Mathematical expectation of a continuous random variable
Dispersion of a continuous random variable
