Коэффициент корреляции показывает. Корреляционный анализ. Подробный пример решения. Пример применения метода корреляционного анализа
В главе 4 мы рассмотрели основные одномерные описательные статистики - меры центральной тенденции и изменчивости, которые применяются для описания одной переменной. В этой главе мы рассмотрим основные коэффициенты корреляции.
Коэффициент корреляции - двумерная описательная статистика, количественная мера взаимосвязи (совместной изменчивости) двух переменных.
История разработки и применения коэффициентов корреляции для исследования взаимосвязей фактически началась одновременно с возникновением измерительного подхода к исследованию индивидуальных различий - в 1870-1880 гг. Пионером в измерении способностей человека, как и автором самого термина «коэффициент корреляции», был Френсис Гальтон, а самые популярные коэффициенты корреляции были разработаны его последователем Карлом Пирсоном. С тех пор изучение взаимосвязей с использованием коэффициентов корреляции является одним из наиболее популярных в психологии занятием.
К настоящему времени разработано великое множество различных коэффициентов корреляции, проблеме измерения взаимосвязи с их помощью посвящены сотни книг. Поэтому, не претендуя на полноту изложения, мы рассмотрим лишь самые важные, действительно незаменимые в исследованиях меры связи - /--Пирсона, r-Спирмена и т-Кендалла". Их общей особенностью является то, что они отражают взаимосвязь двух признаков, измеренных в количественной шкале - ранговой или метрической.
Вообще говоря, любое эмпирическое исследование сосредоточено на изучении взаимосвязей двух или более переменных.
ПРИМЕРЫ
Приведем два примера исследования влияния демонстрации сцен насилия по ТВ на агрессивность подростков. 1. Изучается взаимосвязь двух переменных, измеренных в количественной (ранговой или метрической) шкале: 1)«время просмотра телепередач с насилием»; 2) «агрессивность».
Читается как тау-Кендалла.
ГЛАВА 6. КОЭФФИЦИЕНТЫ КОРРЕЛЯЦИИ
2. Изучается различие в агрессивности 2-х или более групп подростков, отличающихся длительностью просмотра телепередач с демонстрацией сцен насилия.
Во втором примере изучение различий может быть представлено как исследование взаимосвязи 2-х переменных, одна из которых - номинативная (длительность просмотра телепередач). И для этой ситуации также разработаны свои коэффициенты корреляции.
Любое исследование можно свести к изучению корреляций, благо изобретены самые различные коэффициенты корреляции для практически любой исследовательской ситуации. Но в дальнейшем изложении мы будем различать два класса задач:
П исследование корреляций - когда две переменные представлены в числовой шкале;
□ исследование различий - когда хотя бы одна из двух переменных представлена в номинативной шкале.
Такое деление соответствует и логике построения популярных компьютерных статистических программ, в которых в меню Корреляции предлагаются три коэффициента (/--Пирсона, r-Спирмена и х-Кендалла), а для решения других исследовательских задач предлагаются методы сравнения групп.
ПОНЯТИЕ КОРРЕЛЯЦИИ
Взаимосвязи на языке математики обычно описываются при помощи функций, которые графически изображаются в виде линий. На рис. 6.1 изображено несколько графиков функций. Если изменение одной переменной на одну единицу всегда приводит к изменению другой переменной на одну и ту же величину, функция является линейной (график ее представляет прямую линию); любая другая связь - нелинейная. Если увеличение одной переменной связано с увеличением другой, то связь - положительная (прямая); если увеличение одной переменной связано с уменьшением другой, то связь - отрицательная (обратная). Если направление изменения одной переменной не меняется с возрастанием (убыванием) другой переменной, то такая функция - монотонная; в противном случае функцию называют немонотонной.
Функциональные связи, подобные изображенным на рис. 6.1, являются иде-ализациями. Их особенность заключается в том, что одному значению одной переменной соответствует строго определенное значение другой переменной. Например, такова взаимосвязь двух физических переменных - веса и длины тела (линейная положительная). Однако даже в физических экспериментах эмпирическая взаимосвязь будет отличаться от функциональной связи в силу неучтенных или неизвестных причин: колебаний состава материала, погрешностей измерения и пр.
Рис. 6.1. Примеры графиков часто встречающихся функций
В психологии, как и во многих других науках, при изучении взаимосвязи признаков из поля зрения исследователя неизбежно выпадает множество возможных причин изменчивости этих признаков. Результатом является то, что даже существующая в реальности функциональная связь между переменными выступает эмпирически как вероятностная (стохастическая): одному и тому же значению одной переменной соответствует распределение различных значений другой переменной (и наоборот). Простейшим примером является соотношение роста и веса людей. Эмпирические результаты исследования этих двух признаков покажут, конечно, положительную их взаимосвязь. Но несложно догадаться, что она будет отличаться от строгой, линейной, положительной - идеальной математической функции, даже при всех ухищрениях исследователя по учету стройности или полноты испытуемых. (Вряд ли на этом основании кому-то придет в голову отрицать факт наличия строгой функциональной связи между длиной и весом тела.)
Итак, в психологии, как и во многих других науках, функциональная взаимосвязь явлений эмпирически может быть выявлена только как вероятностная связь соответствующих признаков. Наглядное представление о характере вероятностной связи дает диаграмма рассеивания - график, оси которого соответствуют значениям двух переменных, а каждый испытуемый представляет собой точку (рис. 6.2). В качестве числовой характеристики вероятностной связи используются коэффициенты корреляции.
Коэффициент корреляции - это степень связи между двумя переменными. Его расчет дает представление о том, есть ли зависимость между двумя массивами данных. В отличие от регрессии, корреляция не позволяет предсказывать значения величин. Однако расчет коэффициента является важным этапом предварительного статистического анализа. Например, мы установили, что коэффициент корреляции между уровнем прямых иностранных инвестиций и темпом роста ВВП является высоким. Это дает нам представление о том, что для обеспечения благосостояния нужно создать благоприятный климат именно для зарубежных предпринимателей. Не такой уж и очевидный вывод на первый взгляд!
Корреляция и причинность
Пожалуй, нет ни одной сферы статистики, которая бы так прочно вошла в нашу жизнь. Коэффициент корреляции используется во всех областях общественных знаний. Основная его опасность заключается в том, что зачастую его высокими значениями спекулируют для того, чтобы убедить людей и заставить их поверить в какие-то выводы. Однако на самом деле сильная корреляция отнюдь не свидетельствует о причинно-следственной зависимости между величинами.

Коэффициент корреляции: формула Пирсона и Спирмана
Существует несколько основных показателей, которые характеризуют связь между двумя переменными. Исторически первым является коэффициент линейной корреляции Пирсона. Его проходят еще в школе. Он был разработан К. Пирсоном и Дж. Юлом на основе работ Фр. Гальтона. Этот коэффициент позволяет увидеть взаимосвязь между рациональными числами, которые изменяются рационально. Он всегда больше -1 и меньше 1. Отрицательно число свидетельствует об обратно пропорциональной зависимости. Если коэффициент равен нулю, то связи между переменными нет. Равен положительному числу - имеет место прямо пропорциональная зависимость между исследуемыми величинами. Коэффициент ранговой корреляции Спирмана позволяет упростить расчеты за счет построения иерархии значений переменных.

Отношения между переменными
Корреляция помогает найти ответ на два вопроса. Во-первых, является ли связь между переменными положительной или отрицательной. Во-вторых, насколько сильна зависимость. Корреляционный анализ является мощным инструментом, с помощью которого можно получить эту важную информацию. Легко увидеть, что семейные доходы и расходы падают и растут пропорционально. Такая связь считается положительной. Напротив, при росте цены на товар, спрос на него падает. Такую связь называют отрицательной. Значения коэффициента корреляции находятся в пределах между -1 и 1. Нуль означает, что зависимости между исследуемыми величинами нет. Чем ближе полученный показатель к крайним значениям, тем сильнее связь (отрицательная или положительная). Об отсутствии зависимости свидетельствует коэффициент от -0,1 до 0,1. Нужно понимать, что такое значение свидетельствует только об отсутствии линейной связи.

Особенности применения
Использование обоих показателей сопряжено с определенными допущениями. Во-первых, наличие сильной связи, не обуславливает того факта, что одна величина определяет другую. Вполне может существовать третья величина, которая определяет каждую из них. Во-вторых, высокий коэффициент корреляции Пирсона не свидетельствует о причинно-следственной связи между исследуемыми переменными. В-третьих, он показывает исключительно линейную зависимость. Корреляция может использоваться для оценки значимых количественных данных (например, атмосферного давления, температуры воздуха), а не таких категорий, как пол или любимый цвет.
Множественный коэффициент корреляции
Пирсон и Спирман исследовали связь между двумя переменными. Но как действовать в том случае, если их три или даже больше. Здесь на помощь приходит множественный коэффициент корреляции. Например, на валовый национальный продукт влияют не только прямые иностранные инвестиции, но и монетарная и фискальная политика государства, а также уровень экспорта. Темп роста и объем ВВП - это результат взаимодействия целого ряда факторов. Однако нужно понимать, что модель множественной корреляции основывается на целом ряде упрощений и допущений. Во-первых, исключается мультиколлинеарность между величинами. Во-вторых, связь между зависимой и оказывающими на нее влияние переменными считается линейной.

Области использования корреляционно-регрессионного анализа
Данный метод нахождения взаимосвязи между величинами широко применяется в статистике. К нему чаще всего прибегают в трех основных случаях:
- Для тестирования причинно-следственных связей между значениями двух переменных. В результате исследователь надеется обнаружить линейную зависимость и вывести формулу, которая описывает эти отношения между величинами. Единицы их измерения могут быть различными.
- Для проверки наличия связи между величинами. В этом случае никто не определяет, какая переменная является зависимой. Может оказаться, что значение обеих величин обуславливает какой-то другой фактор.
- Для вывода уравнения. В этом случае можно просто подставить в него числа и узнать значения неизвестной переменной.
Человек в поисках причинно-следственной связи
Сознание устроено таким образом, что нам обязательно нужно объяснить события, которые происходят вокруг. Человек всегда ищет связь между картиной мира, в котором он живет, и получаемой информацией. Часто мозг создает порядок из хаоса. Он запросто может увидеть причинно-следственную связь там, где ее нет. Ученым приходится специально учиться преодолевать эту тенденцию. Способность оценивать связи между данными объективно необходима в академической карьере.
Предвзятость средств массовой информации
Рассмотрим, как наличие корреляционной связи может быть неправильно истолковано. Группу британских студентов, отличающихся плохим поведением, опросили относительно того, курят ли их родители. Потом тест опубликовали в газете. Результат показал сильную корреляцию между курением родителей и правонарушениями их детей. Профессор, который проводил это исследование, даже предложил поместить на пачки сигарет предупреждение об этом. Однако существует целый ряд проблем с таким выводом. Во-первых, корреляция не показывает, какая из величин является независимой. Поэтому вполне можно предположить, что пагубная привычка родителей вызвана непослушанием детей. Во-вторых, нельзя с уверенностью сказать, что обе проблемы не появились из-за какого-то третьего фактора. Например, низкого дохода семей. Следует отметить эмоциональный аспект первоначальных выводов профессора, который проводил исследование. Он был ярым противником курения. Поэтому нет ничего удивительного в том, что он интерпретировал результаты своего исследования именно так.

Выводы
Неправильное толкование корреляции как причинно-следственной связи между двумя переменными может стать причиной позорных ошибок в исследованиях. Проблема состоит в том, что оно лежит в самой основе человеческого сознания. Многие маркетинговые трюки построены именно на этой особенности. Понимание различия между причинно-следственной связью и корреляцией позволяет рационально анализировать информацию как в повседневной жизни, так и в профессиональной карьере.
Различные признаки могут быть связаны между собой.
Выделяют 2 вида связи между ними:
- функциональная;
- корреляционная.
Корреляция
в переводе на русский язык – не что иное, как связь.
В случае корреляционной связи прослеживается соответствие нескольких значений одного признака нескольким значениям другого признака. В качестве примеров можно рассмотреть установленные корреляционные связи между:
- длиной лап, шеи, клюва у таких птиц как цапли, журавли, аисты;
- показателями температуры тела и частоты сердечных сокращений.
Для большинства медико-биологических процессов статистически доказано присутствие этого типа связи.
Статистические методы позволяют установить факт существования взаимозависимости признаков. Использование для этого специальных расчетов приводит к установлению коэффициентов корреляции (меры связанности).
Такие расчеты получили название корреляционного анализа. Он проводится для подтверждения зависимости друг от друга 2-х переменных (случайных величин), которая выражается коэффициентом корреляции.
Использование корреляционного метода позволяет решить несколько задач:
- выявить наличие взаимосвязи между анализируемыми параметрами;
- знание о наличии корреляционной связи позволяет решать проблемы прогнозирования. Так, существует реальная возможность предсказывать поведение параметра на основе анализа поведения другого коррелирующего параметра;
- проведение классификации на основе подбора независимых друг от друга признаков.
Для переменных величин:
- относящихся к порядковой шкале, рассчитывается коэффициент Спирмена;
- относящихся к интервальной шкале – коэффициент Пирсона.
Это наиболее часто используемые параметры, кроме них есть и другие.
Значение коэффициента может выражаться как положительным, так и отрицательными.
В первом случае при увеличении значения одной переменной наблюдается увеличение второй. При отрицательном коэффициенте – закономерность обратная.
Для чего нужен коэффициент корреляции?
Случайные величины, связанные между собой, могут иметь совершенно разную природу этой связи. Не обязательно она будет функциональной, случай, когда прослеживается прямая зависимость между величинами. Чаще всего на обе величины действует целая совокупность разнообразных факторов, в случаях, когда они являются общими для обеих величин, наблюдается формирование связанных закономерностей.
Это значит, что доказанный статистически факт наличия связи между величинами не является подтверждением того, что установлена причина наблюдаемых изменений. Как правило, исследователь делает вывод о наличии двух взаимосвязанных следствий.
Свойства коэффициента корреляции
 Этой статистической характеристике присущи следующие свойства:
Этой статистической характеристике присущи следующие свойства:
- значение коэффициента располагается в диапазоне от -1 до +1. Чем ближе к крайним значениям, тем сильнее положительная либо отрицательная связь между линейными параметрами. В случае нулевого значения речь идет об отсутствии корреляции между признаками;
- положительное значение коэффициента свидетельствует о том, что в случае увеличения значения одного признака наблюдается увеличение второго (положительная корреляция);
- отрицательное значение – в случае увеличения значения одного признака наблюдается уменьшение второго (отрицательная корреляция);
- приближение значения показателя к крайним точкам (либо -1, либо +1) свидетельствует о наличии очень сильной линейной связи;
- показатели признака могут изменяться при неизменном значении коэффициента;
- корреляционный коэффициент является безразмерной величиной;
- наличие корреляционной связи не является обязательным подтверждением причинно-следственной связи.
Значения коэффициента корреляции
Охарактеризовать силу корреляционной связи можно прибегнув к шкале Челдока, в которой определенному числовому значению соответствует качественная характеристика.
 В случае положительной корреляции при значении:
В случае положительной корреляции при значении:
- 0-0,3 – корреляционная связь очень слабая;
- 0,3-0,5 – слабая;
- 0,5-0,7 – средней силы;
- 0,7-0,9 – высокая;
- 0,9-1 – очень высокая сила корреляции.
Шкала может использоваться и для отрицательной корреляции. В этом случае качественные характеристики заменяются на противоположные.
Можно воспользоваться упрощенной шкалой Челдока, в которой выделяется всего 3 градации силы корреляционной связи:
- очень сильная – показатели ±0,7 — ±1;
- средняя – показатели ±0,3 — ±0,699;
- очень слабая – показатели 0 — ±0,299.
Данный статистический показатель позволяет не только проверить предположение о существовании линейной взаимосвязи между признаками, но и установить ее силу.
Виды коэффициента корреляции
Коэффициенты корреляции можно классифицировать по знаку и значению:
- положительный;
- нулевой;
- отрицательный.
В зависимости от анализируемых значений рассчитывается коэффициент:
- Пирсона;
- Спирмена;
- Кендала;
- знаков Фехнера;
- конкорддации или множественной ранговой корреляции.
 Корреляционный коэффициент Пирсона используется для установления прямых связей между абсолютными значениями переменных. При этом распределения обоих рядов переменных должны приближаться к нормальному. Сравниваемые переменные должны отличаться одинаковым числом варьирующих признаков. Шкала, представляющая переменные, должна быть интервальной либо шкалой отношений.
Корреляционный коэффициент Пирсона используется для установления прямых связей между абсолютными значениями переменных. При этом распределения обоих рядов переменных должны приближаться к нормальному. Сравниваемые переменные должны отличаться одинаковым числом варьирующих признаков. Шкала, представляющая переменные, должна быть интервальной либо шкалой отношений.
- точного установления корреляционной силы;
- сравнения количественных признаков.
Недостатков использования линейного корреляционного коэффициента Пирсона немного:
- метод неустойчив в случае выбросов числовых значений;
- с помощью этого метода возможно определение корреляционной силы только для линейной взаимосвязи, при других видах взаимных связей переменных следует использовать методы регрессионного анализа.
Ранговая корреляция определяется методом Спирмена, позволяющим статистически изучить связь между явлениями. Благодаря этому коэффициенту вычисляется фактически существующая степень параллелизма двух количественно выраженных рядов признаков, а также оценивается теснота, выявленной связи.
- не требующих точного определения значение корреляционной силы;
- сравниваемые показатели имеют как количественные, так и атрибутивные значения;
- равнения рядов признаков с открытыми вариантами значений.
Метод Спирмена относится к методам непараметрического анализа, поэтому нет необходимости проверять нормальность распределения признака. К тому же он позволяет сравнивать показатели, выраженные в разных шкалах. Например, сравнение значений количества эритроцитов в определенном объеме крови (непрерывная шкала) и экспертной оценки, выражаемой в баллах (порядковая шкала).
На эффективность метода отрицательно влияет большая разница между значениями, сравниваемых величин. Не эффективен метод и в случаях когда измеряемая величина характеризуется неравномерным распределением значений.
Пошаговый расчет коэффициента корреляции в Excel
Расчёт корреляционного коэффициента предполагает последовательное выполнение ряда математических операций.
Приведенная выше формула расчета коэффициента Пирсона, показывает насколько трудоемок этот процесс если выполнять его вручную.
Использование возможностей Excell ускоряет процесс нахождения коэффициента в разы.
Достаточно соблюсти несложный алгоритм действий:
- введение базовой информации – столбец значений х и столбец значений у;
- в инструментах выбирается и открывается вкладка «Формулы»;
- в открывшейся вкладке выбирается «Вставка функции fx»;
- в открывшемся диалоговом окне выбирается статистическая функция «Коррел», позволяющая выполнить расчет корреляционного коэффициента между 2 массивами данных;
- открывшееся окно вносятся данные: массив 1 – диапазон значений столбца х (данные необходимо выделить), массив 2 – диапазон значений столбца у;
- нажимается клавиша «ок», в строке «значение» появляется результат расчета коэффициента;
- вывод относительно наличия корреляционной связи между 2 массивами данных и ее силе.
Задачи корреляционного анализа :
а) Измерение степени связности (тесноты, силы, строгости, интенсивности) двух и более явлений.
б) Отбор факторов, оказывающих наиболее существенное влияние на результативный признак, на основании измерения степени связности между явлениями. Существенные в данном аспекте факторы используют далее в регрессионном анализе.
в) Обнаружение неизвестных причинных связей.
Формы проявления взаимосвязей весьма разнообразны. В качестве самых общих их видов выделяют функциональную (полную) и корреляционную (неполную) связи
.
Корреляционная связь
проявляется в среднем, для массовых наблюдений, когда заданным значениям зависимой переменной соответствует некоторый ряд вероятностных значений независимой переменной. Связь называется корреляционной
, если каждому значению факторного признака соответствует вполне определенное неслучайное значение результативного признака.
Наглядным изображением корреляционной таблицы служит корреляционное поле. Оно представляет собой график, где на оси абсцисс откладываются значения X, по оси ординат – Y, а точками показываются сочетания X и Y. По расположению точек можно судить о наличии связи.
Показатели тесноты связи
дают возможность охарактеризовать зависимость вариации результативного признака от вариации признака-фактора.
Более совершенным показателем степени тесноты корреляционной связи
является линейный коэффициент корреляции
. При расчете этого показателя учитываются не только отклонения индивидуальных значений признака от средней, но и сама величина этих отклонений.
Ключевыми вопросами данной темы являются уравнения регрессионной связи между результативным признаком и объясняющей переменной, метод наименьших квадратов для оценки параметров регрессионной модели, анализ качества полученного уравнения регрессии, построение доверительных интервалов прогноза значений результативного признака по уравнению регрессии.
Пример 2

Система нормальных уравнений.
a n + b∑x = ∑y
a∑x + b∑x 2 = ∑y x
Для наших данных система уравнений имеет вид
30a + 5763 b = 21460
5763 a + 1200261 b = 3800360
Из первого уравнения выражаем а и подставим во второе уравнение:
Получаем b = -3.46, a = 1379.33
Уравнение регрессии:
y = -3.46 x + 1379.33
2. Расчет параметров уравнения регрессии.
Выборочные средние.
![]()
![]()
![]()
Выборочные дисперсии:
Среднеквадратическое отклонение
1.1. Коэффициент корреляции
Ковариация
.
Рассчитываем показатель тесноты связи. Таким показателем является выборочный линейный коэффициент корреляции, который рассчитывается по формуле:
Линейный коэффициент корреляции принимает значения от –1 до +1.
Связи между признаками могут быть слабыми и сильными (тесными). Их критерии оцениваются по шкале Чеддока:
0.1 < r xy < 0.3: слабая;
0.3 < r xy < 0.5: умеренная;
0.5 < r xy < 0.7: заметная;
0.7 < r xy < 0.9: высокая;
0.9 < r xy < 1: весьма высокая;
В нашем примере связь между признаком Y фактором X высокая и обратная.
Кроме того, коэффициент линейной парной корреляции может быть определен через коэффициент регрессии b:
1.2. Уравнение регрессии
(оценка уравнения регрессии).
Линейное уравнение регрессии имеет вид y = -3.46 x + 1379.33

Коэффициент b = -3.46 показывает среднее изменение результативного показателя (в единицах измерения у) с повышением или понижением величины фактора х на единицу его измерения. В данном примере с увеличением на 1 единицу y понижается в среднем на -3.46.
Коэффициент a = 1379.33 формально показывает прогнозируемый уровень у, но только в том случае, если х=0 находится близко с выборочными значениями.
Но если х=0 находится далеко от выборочных значений х, то буквальная интерпретация может привести к неверным результатам, и даже если линия регрессии довольно точно описывает значения наблюдаемой выборки, нет гарантий, что также будет при экстраполяции влево или вправо.
Подставив в уравнение регрессии соответствующие значения х, можно определить выровненные (предсказанные) значения результативного показателя y(x) для каждого наблюдения.
Связь между у и х определяет знак коэффициента регрессии b (если > 0 – прямая связь, иначе - обратная). В нашем примере связь обратная.
1.3. Коэффициент эластичности.
Коэффициенты регрессии (в примере b) нежелательно использовать для непосредственной оценки влияния факторов на результативный признак в том случае, если существует различие единиц измерения результативного показателя у и факторного признака х.
Для этих целей вычисляются коэффициенты эластичности и бета - коэффициенты.
Средний коэффициент эластичности E показывает, на сколько процентов в среднем по совокупности изменится результат у
от своей средней величины при изменении фактора x
на 1% от своего среднего значения.
Коэффициент эластичности находится по формуле:
![]()
Коэффициент эластичности меньше 1. Следовательно, при изменении Х на 1%, Y изменится менее чем на 1%. Другими словами - влияние Х на Y не существенно.
Бета – коэффициент
показывает, на какую часть величины своего среднего квадратичного отклонения изменится в среднем значение результативного признака при изменении факторного признака на величину его среднеквадратического отклонения при фиксированном на постоянном уровне значении остальных независимых переменных:
![]()
Т.е. увеличение x на величину среднеквадратического отклонения S x приведет к уменьшению среднего значения Y на 0.74 среднеквадратичного отклонения S y .
1.4. Ошибка аппроксимации.
Оценим качество уравнения регрессии с помощью ошибки абсолютной аппроксимации. Средняя ошибка аппроксимации - среднее отклонение расчетных значений от фактических:
![]()
![]()
Поскольку ошибка меньше 15%, то данное уравнение можно использовать в качестве регрессии.
Дисперсионный анализ.
Задача дисперсионного анализа состоит в анализе дисперсии зависимой переменной:
∑(y i - y cp) 2 = ∑(y(x) - y cp) 2 + ∑(y - y(x)) 2
где
∑(y i - y cp) 2 - общая сумма квадратов отклонений;
∑(y(x) - y cp) 2 - сумма квадратов отклонений, обусловленная регрессией («объясненная» или «факторная»);
∑(y - y(x)) 2 - остаточная сумма квадратов отклонений.
Теоретическое корреляционное отношение
для линейной связи равно коэффициенту корреляции r xy .
Для любой формы зависимости теснота связи определяется с помощью множественного коэффициента корреляции
:

Данный коэффициент является универсальным, так как отражает тесноту связи и точность модели, а также может использоваться при любой форме связи переменных. При построении однофакторной корреляционной модели коэффициент множественной корреляции равен коэффициенту парной корреляции r xy .
1.6. Коэффициент детерминации.
Квадрат (множественного) коэффициента корреляции называется коэффициентом детерминации, который показывает долю вариации результативного признака, объясненную вариацией факторного признака.
Чаще всего, давая интерпретацию коэффициента детерминации, его выражают в процентах.
R 2 = -0.74 2 = 0.5413
т.е. в 54.13 % случаев изменения х приводят к изменению y. Другими словами - точность подбора уравнения регрессии - средняя. Остальные 45.87 % изменения Y объясняются факторами, не учтенными в модели.
Список литературы
- Эконометрика: Учебник / Под ред. И.И. Елисеевой. – М.: Финансы и статистика, 2001, с. 34..89.
- Магнус Я.Р., Катышев П.К., Пересецкий А.А. Эконометрика. Начальный курс. Учебное пособие. – 2-е изд., испр. – М.: Дело, 1998, с. 17..42.
- Практикум по эконометрике: Учеб. пособие / И.И. Елисеева, С.В. Курышева, Н.М. Гордеенко и др.; Под ред. И.И. Елисеевой. – М.: Финансы и статистика, 2001, с. 5..48.
» Статистика
Статистика и обработка данных в психологии
(продолжение)
Корреляционный анализ
При изучении корреляций стараются установить, существует ли какая-то связь между двумя показателями в одной выборке (например, между ростом и весом детей или между уровнем IQ и школьной успеваемостью) либо между двумя различными выборками (например, при сравнении пар близнецов), и если эта связь существует, то сопровождается ли увеличение одного показателя возрастанием (положительная корреляция) или уменьшением (отрицательная корреляция) другого.
Иными словами, корреляционный анализ помогает установить, можно ли предсказывать возможные значения одного показателя, зная величину другого.
До сих пор при анализе результатов нашего опыта по изучению действия марихуаны мы сознательно игнорировали такой показатель, как время реакции. Между тем было бы интересно проверить, существует ли связь между эффективностью реакций и их быстротой. Это позволило бы, например, утверждать, что чем человек медлительнее, тем точнее и эффективнее будут его действия и наоборот.
С этой целью можно использовать два разных способа: параметрический метод расчета коэффициента Браве-Пирсона (r) и вычисление коэффициента корреляции рангов Спирмена (r s), который применяется к порядковым данным, т.е. является непараметрическим. Однако разберемся сначала в том, что такое коэффициент корреляции.
Коэффициент корреляции
Коэффициент корреляции - это величина, которая может варьировать в пределах от +1 до -1. В случае полной положительной корреляции этот коэффициент равен плюс 1, а при полной отрицательной - минус 1. На графике этому соответствует прямая линия, проходящая через точки пересечения значений каждой пары данных:

В случае же если эти точки не выстраиваются по прямой линии, а образуют «облако», коэффициент корреляции по абсолютной величине становится меньше единицы и по мере округления этого облака приближается к нулю:
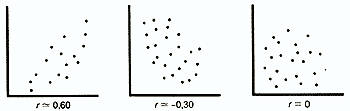
В случае если коэффициент корреляции равен 0, обе переменные полностью независимы друг от друга.
В гуманитарных науках корреляция считается сильной, если ее коэффициент выше 0,60; если же он превышает 0,90, то корреляция считается очень сильной. Однако для того, чтобы можно было делать выводы о связях между переменными, большое значение имеет объем выборки: чем выборка больше, тем достовернее величина полученного коэффициента корреляции. Существуют таблицы с критическими значениями коэффициента корреляции Браве-Пирсона и Спирмена для разного числа степеней свободы (оно равно числу пар за вычетом 2, т. е. n- 2). Лишь в том случае, если коэффициенты корреляции больше этих критических значений, они могут считаться достоверными. Так, для того чтобы коэффициент корреляции 0,70 был достоверным, в анализ должно быть взято не меньше 8 пар данных (h =n -2=6) при вычислении r (см. табл. 4 в Приложении) и 7 пар данных (h =n-2= 5) при вычислении r s (табл. 5 в Приложении).
Хотелось бы еще раз подчеркнуть, что сущность этих двух коэффициентов несколько различна. Отрицательный коэффициент r указывает на то, что эффективность чаще всего тем выше, чем время реакции меньше, тогда как при вычислении коэффициента r s требовалось проверить, всегда ли более быстрые испытуемые реагируют более точно, а более медленные - менее точно.
Коэффициент корреляции Браве-Пирсона (r) - этопараметрический показатель, для вычисления которого сравнивают средние и стандартные отклонения результатов двух измерений. При этом используют формулу (у разных авторов она может выглядеть по-разному)
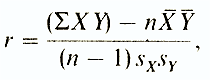
где ΣXY -
сумма произведений
данных из каждой пары;
n-число пар;
X
- средняя для данных переменной X;
Y
-
средняя для данных
переменной Y
S x -
стандартное отклонение для
распределения х;
S y -
стандартное отклонение для распределения у
Коэффициент корреляции рангов Спирмена (r s ) - это непараметрический показатель, с помощью которого пытаются выявить связь между рангами соответственных величин в двух рядах измерений.
Этот коэффициент рассчитывать проще, однако результаты получаются менее точными, чем при использовании r. Это связано с тем, что при вычислении коэффициента Спирмена используют порядок следования данных, а не их количественные характеристики и интервалы между классами.
Дело в том, что при использовании коэффициента корреляции рангов Спирмена (r s) проверяют только, будет ли ранжирование данных для какой-либо выборки таким же, как и в ряду других данных для этой выборки, попарно связанных с первыми (например, будут ли одинаково «ранжироваться» студенты при прохождении ими как психологии, так и математики, или даже при двух разных преподавателях психологии?). Если коэффициент близок к +1, то это означает, что оба ряда практически совпадают, а если этот коэффициент близок к -1, можно говорить о полной обратной зависимости.
Коэффициент r s вычисляют по формуле

где d - разность между рангами сопряженных значений признаков (независимо от ее знака), а - число пар.
Обычно этот непараметрический тест используется в тех случаях, когда нужно сделать какие-то выводы не столько об интервалах между данными, сколько об их рангах, а также тогда, когда кривые распределения слишком асимметричны и не позволяют использовать такие параметрические критерии, как коэффициент r (в этих случаях бывает необходимо превратить количественные данные в порядковые).
Резюме
Итак, мы рассмотрели различные параметрические и непараметрические статистические методы, используемые в психологии. Наш обзор был весьма поверхностным, и главная задача его заключалась в том, чтобы читатель понял, что статистика не так страшна, как кажется, и требует в основном здравого смысла. Напоминаем, что данные «опыта», с которыми мы здесь имели дело, - вымышленные и не могут служить основанием для каких-либо выводов. Впрочем, подобный эксперимент стоило бы действительно провести. Поскольку для этого опыта была выбрана сугубо классическая методика, такой же статистический анализ можно было бы использовать во множестве различных экспериментов. В любом случае нам кажется, что мы наметили какие-то главные направления, которые могут оказаться полезны тем, кто не знает, с чего начать статистический анализ полученных результатов.
Литература
- Годфруа Ж. Что такое психология. - М., 1992.
- Chatillon G., 1977. Statistique en Sciences humaines, Trois-Rivieres, Ed. SMG.
- Gilbert N.. 1978. Statistiques, Montreal, Ed. HRW.
- Moroney M.J., 1970. Comprendre la statistique, Verviers, Gerard et Cie.
- Siegel S., 1956. Non-parametric Statistic, New York, MacGraw-Hill Book Co.
Приложение Таблицы
Примечания. 1) Для больших выборок или уровня значимости меньше 0,05 следует обратиться к таблицам в пособиях по статистике.
2) Таблицы значений других непараметрических критериев можно найти в специальных руководствах (см. библиографию).
| Таблица 1. Значения критерия t Стьюдента | |
| h | 0,05 |
| 1 | 6,31 |
| 2 | 2,92 |
| 3 | 2,35 |
| 4 | 2,13 |
| 5 | 2,02 |
| 6 | 1,94 |
| 7 | 1,90 |
| 8 | 1,86 |
| 9 | 1,83 |
| 10 | 1,81 |
| 11 | 1,80 |
| 12 | 1,78 |
| 13 | 1,77 |
| 14 | 1,76 |
| 15 | 1,75 |
| 16 | 1,75 |
| 17 | 1,74 |
| 18 | 1,73 |
| 19 | 1,73 |
| 20 | 1,73 |
| 21 | 1,72 |
| 22 | 1,72 |
| 23 | 1,71 |
| 24 | 1,71 |
| 25 | 1,71 |
| 26 | 1,71 |
| 27 | 1,70 |
| 28 | 1,70 |
| 29 | 1,70 |
| 30 | 1,70 |
| 40 | 1,68 |
| ¥ | 1,65 |
| Таблица 2. Значения критерия χ 2 | |
| h | 0,05 |
| 1 | 3,84 |
| 2 | 5,99 |
| 3 | 7,81 |
| 4 | 9,49 |
| 5 | 11,1 |
| 6 | 12,6 |
| 7 | 14,1 |
| 8 | 15,5 |
| 9 | 16,9 |
| 10 | 18,3 |
| Таблица 3. Достоверные значения Z | |
| р | Z |
| 0,05 | 1,64 |
| 0,01 | 2,33 |
| Таблица 4. Достоверные (критические) значения r | ||
| h =(N-2) | р= 0,05 (5%) | |
| 3 | 0,88 | |
| 4 | 0,81 | |
| 5 | 0,75 | |
| 6 | 0,71 | |
| 7 | 0,67 | |
| 8 | 0,63 | |
| 9 | 0,60 | |
| 10 | 0,58 | |
| 11 | 0.55 | |
| 12 | 0,53 | |
| 13 | 0,51 | |
| 14 | 0,50 | |
| 15 | 0,48 | |
| 16 | 0,47 | |
| 17 | 0,46 | |
| 18 | 0,44 | |
| 19 | 0,43 | |
| 20 | 0,42 | |
| Таблица 5. Достоверные (критические) значения r s | |
| h =(N-2) | р = 0,05 |
| 2 | 1,000 |
| 3 | 0,900 |
| 4 | 0,829 |
| 5 | 0,714 |
| 6 | 0,643 |
| 7 | 0,600 |
| 8 | 0,564 |
| 10 | 0,506 |
| 12 | 0,456 |
| 14 | 0,425 |
| 16 | 0,399 |
| 18 | 0,377 |
| 20 | 0,359 |
| 22 | 0,343 |
| 24 | 0,329 |
| 26 | 0,317 |
| 28 | 0,306 |
