Структурные особенности молекулы днк. Строение, функции и свойства днк. Строение молекул ДНК
Открытие генетической роли ДНК
ДНК была открыта Иоганном Фридрихом Мишером в 1869 году. Из остатков клеток, содержащихся в гное, он выделил вещество, в состав которого входят азот и фосфор. Впервые нуклеиновую кислоту, свободную от белков, получил Р. Альтман в 1889 г., который и ввел этот термин в биохимию. Лишь к середине 1930-х годов было доказано, что ДНК и РНК содержатся в каждой живой клетке. Первостепенная роль в утверждении этого фундаментального положения принадлежит А. Н. Белозерскому, впервые выделившему ДНК из растений. Постепенно было доказано, что именно ДНК, а не белки, как считалось раньше, является носителем генетической информации. О. Эверину, Колину Мак-Леоду и Маклину Мак-Карти (1944 г.) удалось показать, что за так называемую трансформацию (приобретение болезнетворных свойств безвредной культурой в результате добавления в неё мёртвых болезнетворных бактерий) отвечают выделенные из пневмококков ДНК. Эксперимент американских учёных (эксперимент Херши - Чейз, 1952 г.) с помеченными радиоактивными изотопами белками и ДНК бактериофагов показали, что в заражённую клетку передаётся только нуклеиновая кислота фага, а новое поколение фага содержит такие же белки и нуклеиновую кислоту, как исходный фаг.Вплоть до 50-х годов XX века точное строение ДНК, как и способ передачи наследственной информации, оставалось неизвестным. Хотя и было доподлинно известно, что ДНК состоит из нескольких цепочек, состоящих из нуклеотидов, никто не знал точно, сколько этих цепочек и как они соединены.Структура двойной спирали ДНК была предложена Френсисом Криком и Джеймсом Уотсоном в 1953 году на основании рентгеноструктурных данных, полученных Морисом Уилкинсом и Розалинд Франклин, и «правил Чаргаффа», согласно которым в каждой молекуле ДНК соблюдаются строгие соотношения, связывающие между собой количество азотистых оснований разных типов. Позже предложенная Уотсоном и Криком модель строения ДНК была доказана, а их работа отмечена Нобелевской премией по физиологии или медицине 1962 г. Среди лауреатов не было скончавшейся к тому времени Розалинды Франклин, так как премия не присуждается посмертно.В 1960 г. сразу в нескольких лабораториях был открыт фермент РНК-полимераза, осуществляющий синтез РНК на ДНК-матрицах. Генетический аминокислотный код был полностью расшифрован в 1961–1966 гг. усилиями лабораторий М. Ниренберга, С. Очоа и Г. Кораны.
Химический состав и структурная организация молекулы днк.
ДНК - дезоксирибонуклеиновая кислота. Молекула ДНК – это самый крупный биополимер, мономером которого является нуклеотид. Нуклеотид состоит из остатков 3 веществ: 1 – азотистого основания; 2 – углевода дезоксирибозы; 3 - фосфорной кислоты (рисунок – строение нуклеотида). Нуклеотиды, участвующие в образовании молекулы ДНК отличаются друг от друга азотистыми основаниями. Азотистые основание: 1 – Цитозин и Тимин (производные пиримидина) и 2 – Аденин и Гуанин (производные пурина). Соединение нуклеотидов в нити ДНК происходит через углевод одного нуклеотида и остаток фосфорный кислоты соседнего (рисунок – строение полинуклеотидной цепи). Правило Чаргаффа (1951г.): число пуриновых оснований в ДНК всегда равно числу пиримидиновых, А=Т Г=Ц.
1953г. Дж. Уотсон и Ф. Крик – Представили модель строения молекулы ДНК (рисунок – строение молекулы ДНК).
Первичная структура – последовательность расположения мономерных звеньев (мононуклеотидов) в линейных полимерах. Цепь стабилизируется 3,5 – фосфодиэфирными связями.Вторичная структура – двойная спираль, формирование которой определяется межнуклеотидными водородными связями, которые образуются между основаниями входящими в канонические пары А-Т (2 водородные связи) и Г-Ц (3 водородные связи). Цепи удерживаются стекинг-взаимодействиями, электростатическими взаимодействиями,Ван-Дер-Ваальсовыми взаимодействиями.Третичная структура – общая форма молекул биополимеров. Сверхспиральная структура – когда замкнутая двойная спираль образует не кольцо, а структуру с витками более высокого порядка (обеспечивает компактность).Четвертичная структура – укладка молекул в полимолекулярные ансамбли. Для нуклеиновых кислот - это ансамбли, включающие молекулы белков.
DNA Logic - это технология ДНК-вычислений, которая сегодня находится в зачаточном состоянии, однако в будущем на нее возлагаются большие надежды. Биологические нанокомпьютеры, вживляемые в живые организмы, пока видятся нам как нечто фантастическое, нереальное. Но то, что нереально сегодня, уже завтра может оказаться чем-то обыденным и настолько естественным, что трудно будет представить, как без этого можно было обходиться в прошлом.
Итак, ДНК-вычисления - это раздел области молекулярных вычислений на границе молекулярной биологии и компьютерных наук. Основная идея ДНК-вычислений - построение новой парадигмы, создание новых алгоритмов вычислений на основе знаний о строении и функциях молекулы ДНК и операций, которые выполняются в живых клетках над молекулами ДНК при помощи различных ферментов. К перспективам ДНК-вычислений относится создание биологического нанокомпьютера, который будет способен хранить терабайты информации при объеме в несколько микрометров. Такой компьютер можно будет вживлять в клетку живого организма, а его производительность будет исчисляться миллиардами операций в секунду при энергопотреблении не более одной миллиардной доли ватта.
Преимущества ДНК в компьютерных технологиях
Для современных процессоров и микросхем в качестве строительного материала используется кремний. Но возможности кремния не беспредельны, и в конечном счете мы подойдем к той черте, когда дальнейший рост вычислительной мощности процессоров окажется исчерпан. А потому перед человечеством уже сейчас остро стоит проблема поиска новых технологий и материалов, которые смогли бы в будущем заменить кремний.
Молекулы ДНК могут оказаться тем самым материалом, который впоследствии заменит кремниевые транзисторы с их бинарной логикой. Достаточно сказать, что всего один фунт (453 г) ДНК-молекул обладает емкостью для хранения данных, которая превосходит суммарную емкость всех современных электронных систем хранения данных, а вычислительная мощность ДНК-процессора размером с каплю будет выше самого мощного современного суперкомпьютера.
Более 10 триллионов ДНК-молекул занимают объем всего в 1 см3. Однако такого количества молекул достаточно для хранения объема информации в 10 Тбайт, при этом они могут производить 10 трлн операций в секунду.
Еще одно преимущество ДНК-процессоров в сравнении с обычными кремниевыми процессорами заключается в том, что они могут производить все вычисления не последовательно, а параллельно, что обеспечивает выполнение сложнейших математических расчетов буквально за считаные минуты. Традиционным компьютерам для выполнения таких расчетов потребовались бы месяцы и годы.
Строение молекул ДНК
Как известно, современные компьютеры работают с бинарной логикой, подразумевающей наличие всего двух состояний: логического нуля и единицы. Используя двоичный код, то есть последовательность нулей и единиц, можно закодировать любую информацию. В молекулах ДНК имеется четыре базовых основания: аденин (A), гуанин (G), цитозин (C) и тимин (T), связанных друг с другом в цепочку. То есть молекула ДНК (одинарная цепочка) может иметь, например, такой вид: ATTTACGGCC - здесь используется не двоичная, а четверичная логика. И подобно тому, как в двоичной логике любую информацию можно закодировать в виде последовательности нулей и единиц, в молекулах ДНК можно кодировать любую информацию путем сочетания базовых оснований.
Базовые основания в молекулах ДНК находятся друг от друга на расстоянии 0,34 нанометра, что обусловливает их огромную информативную емкость - линейная плотность составляет 18 Мбит/дюйм. Если же говорить о поверхностной информативной плотности, предполагая, что на одно базовое основание приходится площадь в 1 квадратный нанометр, то она составляет более миллиона гигабит на квадратный дюйм. Для сравнения отметим, что поверхностная плотность записи современных жестких дисков составляет порядка 7 Гбит/дюйм 2.
Другое важное свойство ДНК-молекул заключается в том, что они могут иметь форму регулярной двойной спирали, диаметр которой составляет всего 2 нм. Такая спираль состоит из двух цепей (последовательностей базовых оснований), причем содержание первой цепи строго соответствует содержанию второй.
Это соответствие достигается благодаря наличию водородных связей между направленными навстречу друг другу основаниями двух цепей - попарно G и C или A и T. Описывая это свойство двойной спирали, молекулярные биологи говорят, что цепи ДНК комплементарны за счет образования пар G-C и A-T.
К примеру, если последовательность S записывается как ATTACGTCG, то дополняющая ее последовательность S’ будет иметь вид TAATGCAGC.
Процесс соединения двух одинарных цепочек ДНК путем связывания комплементарных оснований в регулярную двойную спираль называется ренатурацией, а обратный процесс, то есть разъединение двойной цепочки и получение двух одинарных цепочек, - денатурацией (рис. 1).
Рис. 1. Процессы ренатурации и денатурации
Комплементарная особенность строения ДНК-молекул может использоваться при ДНК-вычислениях. К примеру, на основе дополняющих друг друга последовательностей можно реализовать мощнейший механизм коррекции ошибок, который чем-то напоминает технологию зеркалирования данных RAID Level 1.
Базовые операции над ДНК-молекулами
Для различных манипуляций над ДНК-молекулами используются различные энзимы (ферменты). И точно так же, как современные микропроцессоры имеют набор базовых операций типа сложения, сдвига, логических операций AND, OR и NOT NOR, ДНК-молекулы под воздействием энзимов могут выполнять такие базовые операции, как разрезание, копирование, вставка и др. Причем все операции над ДНК-молекулами можно производить параллельно и независимо от других операций, к примеру дополнение цепочки ДНК осуществляется при воздействии на исходную молекулу ферментов - полимераз. Для работы полимеразы необходимо наличие одноцепочечной молекулы (матрицы), определяющей добавляемую цепочку по принципу комплементарности, праймера (небольшого двухцепочечного участка) и свободных нуклеотидов в растворе. Процесс дополнения цепочки ДНК показан на рис. 2.
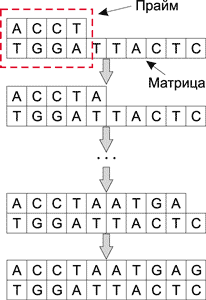
Рис. 2. Процесс дополнения цепочки ДНК
при воздействии на исходную молекулу полимеразы
Существуют полимеразы, которым не требуются матрицы для удлинения цепочки ДНК. Например, терминальная трансфераза добавляет одинарные цепочки ДНК к обоим концам двухцепочечной молекулы. Таким образом можно конструировать произвольную цепь ДНК (рис. 3).

Рис. 3. Процесс удлинения цепочки ДНК
За укорачивание и разрезание молекул ДНК отвечают ферменты - нуклеазы. Различают эндонуклеазы и экзонуклеазы. Последние могут укорачивать и одноцепочечные и двухцепочечные молекулы с одного или с обоих концов (рис. 4), а эндонуклеазы - только с концов.
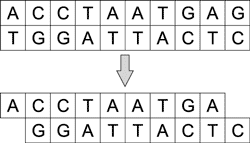
Рис. 4. Процесс укорачивания молекулы
ДНК под воздействием экзонуклеазы
Разрезание молекул ДНК возможно под воздействием сайт-специфичных эндонуклеазов - рестриктазов, которые разрезают их в определенном месте, закодированном последовательностью нуклеотидов (сайтом узнавания). Разрез может быть прямым или несимметричным и проходить по сайту узнавания либо вне его. Эндонуклеазы разрушают внутренние связи в молекуле ДНК (рис. 5).
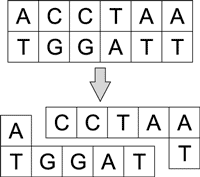
Рис. 5. Разрезание молекулы ДНК
под воздействием рестриктазов
Сшивка - операция, обратная разрезанию, - происходит под воздействием ферментов - лигазов. «Липкие концы» соединяются вместе с образованием водородных связей. Лигазы служат для того, чтобы закрыть насечки, то есть способствовать образованию в нужных местах фосфодиэфирных связей, соединяющих основания друг с другом в пределах одной цепочки (рис. 6).

Рис. 6. Сшивка ДНК-молекул под воздействием лигазов
Еще одна интересная операция над ДНК-молекулами, которую можно отнести к числу базовых, - это модификация. Она используется для того, чтобы рестриктазы не смогли найти определенный сайт и не разрушили молекулу. Существует несколько типов модифицирующих ферментов - метилазы, фосфатазы и т.д.
Метилаза имеет тот же сайт узнавания, что и соответствующая рестриктаза. При нахождении нужной молекулы метилаза модифицирует участок с сайтом так, что рестриктаза уже не сможет идентифицировать эту молекулу.
Копирование, или размножение, ДНК-молекул осуществляется в ходе полимеразной цепной реакции (Polymerase Chain Reaction, PCR) - рис. 7. Процесс копирования можно разделить на несколько стадий: денатурация, праймирование и удлинение. Он происходит лавинообразно. На первом шаге из одной молекулы образуются две, на втором - из двух молекул - четыре, а после n-шагов получается уже 2n молекул.

Рис. 7. Процесс копирования ДНК-молекулы
Еще одна операция, которую можно производить над ДНК-молекулами, - это секвенирование, то есть определение последовательности нуклеотидов в ДНК. Для секвенирования цепочек разной длины применяют различные методы. При помощи метода праймер-опосредованной прогулки удается на одном шаге секвенировать последовательность в 250-350 нуклеотидов. После открытия рестриктаз стало возможным секвенировать длинные последовательности по частям.
Ну и последняя процедура, которую мы упомянем, - это гель-электрофорез, используемый для разделения молекул ДНК по длине. Если молекулы поместить в гель и приложить постоянное электрическое поле, то они будут двигаться по направлению к аноду, причем более короткие молекулы будут двигаться быстрее. Используя данное явление, можно реализовать сортировку ДНК-молекул по длине.
ДНК-вычисления
ДНК-молекулы со своей уникальной формой строения и возможностью реализовать параллельные вычисления позволяют по-другому взглянуть на проблему компьютерных вычислений. Традиционные процессоры выполняют программы последовательно. Несмотря на существование многопроцессорных систем, многоядерных процессоров и различных технологий, направленных на повышение уровня параллелизма, в своей основе все компьютеры, построенные на основе фон-неймановской архитектуры, являются устройствами с последовательным режимом выполнения команд. Все современные процессоры реализуют следующий алгоритм обработки команд и данных: выборка команд и данных из памяти и исполнение инструкций над выбранными данными. Этот цикл повторяется многократно и с огромной скоростью.
ДНК-вычисления имеют в своей основе абсолютно иную, параллельную архитектуру и в ряде случаев именно благодаря этому способны с легкостью рассчитывать те задачи, для решения которых компьютерам на базе фон-неймановской архитектуры потребовались бы годы.
Эксперимент Эдлмана
История ДНК-вычислений начинается в 1994 году. Именно тогда Леонард М. Эдлман (Leonard M. Adleman) попытался решить весьма тривиальную математическую задачу абсолютно нетривиальным способом - с использованием ДНК-вычислений. Фактически это было первой демонстраций прототипа биологического компьютера на основе ДНК-вычислений.
Задача, которую Эдлман выбрал для выполнения с помощью ДНК-вычислений, известна как поиск гамильтонова пути в графе или выбор маршрута путешествия (traveling salesman problem). Смысл ее заключается в следующем: имеется несколько городов, которые необходимо посетить, причем побывать в каждом городе можно только один раз.
Зная пункт отправления и конечный пункт, необходимо определить маршрут путешествия (если он существует). При этом маршрут составляется с учетом возможных авиаперелетов и коннектов различных авиарейсов.
Итак, предположим, что имеется всего четыре города (в эксперименте Эдлмана использовалось семь городов): Атланта (Atlanta), Бостон (Boston), Детройт (Detroit) и Чикаго (Chicago). Перед путешественником ставится задача выбрать маршрут, чтобы попасть из Атланты в Детройт, побывав при этом в каждом городе только один раз. Схемы возможных сообщений между городами показаны на рис. 8.

Рис. 8. Схемы возможных сообщений
между городами
Нетрудно заметить (для этого требуется всего несколько секунд), что единственно возможный маршрут (гамильтонов путь) следующий: Атланта - Бостон - Чикаго - Детройт.
Действительно, при небольшом количестве городов составить такой маршрут довольно просто. Но с увеличением их числа сложность решения задачи экспоненциально возрастает и становится трудновыполнимой не только для человека, но и для компьютера.
Так, на рис. 9 показан граф из семи вершин с указанием возможных переходов между ними. Для поиска гамильтонова пути обычному человеку требуется не более одной минуты. Именно такой граф был использован в эксперименте Эдлмана. На рис. 10 представлен граф из 12 вершин - в этом случае поиск гамильтонова пути оказывается уже не такой простой задачей. Вообще, сложность решения задачи поиска гамильтонова пути возрастает экспоненциально с ростом числа вершин в графе. К примеру, для графа из 10 вершин существует 106 возможных путей; для графа из 20 вершин - 1012, а для графа из 100 вершин - 10100 вариантов. Понятно, что в последнем случае для генерации всех возможных путей и их проверки потребуется огромное время даже для современного суперкомпьютера.

Рис. 9. Поиск оптимального маршрута путешествия

Рис. 10. Граф, состоящий из 12 вершин
Итак, вернемся к нашему примеру с поиском гамильтонова пути в случае четырех городов (см. рис. 8).
Для решения данной задачи с использованием ДНК-вычислений Эдлман закодировал название каждого города в виде одной цепочки ДНК, причем каждая из них содержала 20 базовых оснований. Для простоты мы будем кодировать каждый город ДНК-цепочкой из восьми оснований. ДНК-коды городов показаны в табл. 1. Обратите внимание, что цепочка длиной в восемь базовых оснований оказывается избыточной для кодирования всего четырех городов.

Таблица 1. ДНК-коды городов
Отметим, что для каждого ДНК-кода города, который определяет одинарную ДНК-цепочку, существует и комплементарная цепочка, то есть комплементарный ДНК-код города, причем и ДНК-код города, и комплементраный код абсолютно равноправны.
Далее с помощью одинарных ДНК-цепочек необходимо закодировать все возможные перелеты (Атланта - Бостон, Бостон - Детройт, Чикаго - Детройт и т.д.). Для этого использовался следующий подход. Из названия города отправления брались четыре последних базовых основания, а из названия города прибытия - четыре первых.
К примеру, перелету Атланта - Бостон будет соответствовать следующая последовательность: GCAG TCGG (рис. 11).

Рис. 11. Кодирование перелетов между городами
ДНК-кодирование всех возможных перелетов показано в табл. 2.

Таблица 2. ДНК-коды всех возможных перелетов
Итак, после того как готовы коды городов и возможных перелетов между ними, можно непосредственно переходить к вычислению гамильтонова пути. Процесс вычисления состоит из четырех этапов:
- Сгенерировать все возможные маршруты.
- Отобрать маршруты, которые начинаются в Атланте и заканчиваются Детройтом.
- Выбрать маршруты, длина которых соответствует количеству городов (в нашем случае длина маршрута составляет четыре города).
- Выбрать маршруты, в которых каждый город присутствует только один раз.
Итак, на первом этапе мы должны сгенерировать все возможные маршруты. Напомним, что правильный маршрут соответствует перелетам Атланта - Бостон - Чикаго - Детройт. Этому маршруту соответствует ДНК-молекула GCAG TCGG ACTG GGCT ATGT CCGA.
Для того чтобы сгенерировать все возможные маршруты достаточно поместить в пробирку все необходимые и заранее заготовленные ингредиенты, то есть ДНК-молекулы, соответствующие всем возможным перелетам, и ДНК-молекулы, соответствующие всем городам. Но вместо того, чтобы применять одинарные ДНК-цепочки, соответствующие названиям городов, необходимо использовать комплементарные им ДНК-цепочки, то есть вместо ДНК-цепочки ACTT GCAG, соответствующей Атланте, будем применять комплементарную ДНК-цепочку TGAA CGTC и т.д., поскольку ДНК-код города и комплементраный код абсолютно равноправны.
Далее все эти молекулы (достаточно буквально щепотки, которая будет содержать порядка 1014 различных молекул) помещаем в воду, добавляем лигазов, произносим заклинание и… буквально через несколько секунд получаем все возможные маршруты.
Процесс образования цепочек ДНК, соответствующих различным маршрутам, происходит следующим образом. Рассмотрим, к примеру, цепочку GCAG TCGG, отвечающую за перелет Атланта - Бостон. Вследствие высокой концентрации различных молекул, данная цепочка обязательно встретится с комплементарной ДНК-цепочкой AGCC TGAC, соответствующей Бостону. Поскольку группы TCGG и AGCC комплементарны друг другу, то за счет образования водородных связей эти цепочки сцепятся друг с другом (рис. 12).
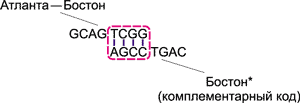
Рис. 12. Сцепление цепочек, соответствующих
перелету Атланта - Бостон и Бостону
Теперь образовавшаяся цепочка неминуемо встретится с ДНК-цепочкой ACTG GGCT, соответствующей авиаперелету Бостон - Чикаго, и поскольку группа ACTG (первые четыре основания в этой цепочке) комплементарна группе TGAC (последние четыре основания в комплементарном коде Бостона), то ДНК-цепочка ACTG GGCT присоединится к уже образовавшейся цепочке. Далее к этой цепочке таким же образом присоединится ДНК-цепочка, соответствующая городу Чикаго (комплементарный код), а затем и цепочка авиаперелета Чикаго - Детройт. Процесс образования маршрута показан на рис. 13.

Рис. 13. Процесс образования ДНК-цепочки, соответствующей маршруту
Атланта - Бостон - Чикаго - Детройт
Мы рассмотрели пример образования только одного маршрута (причем это именно гамильтонов маршрут). Аналогичным образом получаются и все остальные возможные маршруты (например, Атланта - Бостон - Атланта - Детройт). Важно, что все маршруты формируются одновременно, то есть параллельно. Причем время, требуемое для создания всех возможных маршрутов в данной задаче и всех маршрутов в задаче с 10 или 20 городами, абсолютно одинаково (лишь бы хватило исходных ДНК-молекул). Собственно, именно в параллельном алгоритме ДНК-вычислений и заключается основное преимущество в сравнении с фон-неймановской архитектурой.
Итак, в пробирке образованы ДНК-молекулы, соответствующие всем возможным маршрутам. Однако это еще не решение задачи - нам необходимо выделить ту единственную ДНК-молекулу, которая отвечает за гамильтонов маршрут. Поэтому на следующем этапе необходимо отобрать молекулы, соответствующие маршрутам, начинающимся в Атланте и заканчивающимся в Детройте.
Для этого используется полимеразная цепная реакция (PCR), в результате которой создается множество копий только тех ДНК-цепочек, которые начинаются с кода Атланты и заканчиваются кодом Детройта.
Для реализации полимеразной цепной реакции применяются два прайма: GCAG и GGCT. Процесс копирования ДНК-модекул, начинающихся с ДНК-кода Атланты и заканчивающихся ДНК-кодом Детройта, показан на рис. 14.

Рис. 14. Процесс копирования ДНК-молекул в ходе PCR-реакции
Отметим, что в присутствии праймов GCAG и GGCT будут копироваться и те ДНК-молекулы, которые начинаются с ДНК-кодов Атланты, но не заканчиваются ДНК-кодом Детройта (под действием прайма GCAG), а также ДНК-молекулы, которые заканчиваются ДНК-кодом Детройта, но не начинаются с ДНК-кода Атланты (под действием прайма GGCT). Понятно, что скорость копирования таких молекул будет гораздо ниже скорости копирования ДНК-молекул, начинающихся с ДНК-кода Атланты и заканчивающихся ДНК-кодом Детройта. Следовательно, после PCR-реакции мы получим преобладающее количество ДНК-молекул в форме регулярной двойной спирали, соответствующих маршрутам, начинающимся в Атланте и заканчивающимся в Детройте.
На следующем этапе необходимо выделить молекулы нужной длины, то есть те, что содержат ДНК-коды ровно четырех городов. Для этого используется гель-электрофорез, что позволяет отсортировать молекулы по длине. В результате мы получаем молекулы нужной длины (ровно четыре города), начинающиеся с кода Атланты и заканчивающиеся кодом Детройта.
Теперь необходимо убедиться, что в отобранных молекулах код каждого города присутствует только один раз. Эта операция реализуется с применением процесса, известного как affinity purification.
Для данной операции используется микроскопический магнитный шарик диаметром порядка одного микрона. К нему притягиваются комлементарные ДНК-коды того или иного города, которые выполняют функцию пробы. К примеру, если требуется проверить, присутствует ли в исследуемой ДНК-цепочке код города Бостона, то необходимо сначала поместить магнитный шарик в пробирку с ДНК-молекулами, соответствующими ДНК-кодам Бостона. В результате мы получим магнитный шарик, облепленный нужными нам пробами. Затем этот шарик помещается в пробирку с исследуемыми ДНК-цепочками - в результате к нему (за счет образования водородных связей между комплементарными группами) притянутся ДНК-цепочки, в которых присутствует комплементарный код Бостона. Далее шарик с отсортированными молекулами вынимается и помещается в новый раствор, из которого затем удаляется (при повышении температуры ДНК-молекулы отваливаются от шарика). Данная процедура (сортировка) повторяется последовательно для каждого города, и в результате мы получаем только те молекулы, в которых содержатся ДНК-коды всех городов, а значит, и маршруты, соответствующие гамильтонову пути. Фактически задача решена - осталось лишь просчитать ответ.
Заключение
Эдлман продемонстрировал решение задачи поиска гамильтонова пути на примере всего семи городов и потратил на это семь дней. Это был первый эксперимент, продемонстрировавший возможности ДНК-вычислений. Фактически Эдлман доказал, что, пользуясь вычислениями на ДНК, можно эффективно решать задачи переборного характера, и обозначил технику, которая в дальнейшем послужила основой для создания модели параллельной фильтрации.
Впрочем, многие исследователи не испытывают оптимизма по поводу будущего биологических компьютеров. Вот лишь маленький пример. Если бы подобным методом понадобилось найти гамильтонов путь в графе, состоящем из 200 вершин, потребовалось бы количество ДНК-молекул, сопоставимое по весу со всей нашей планетой! Это принципиальное ограничение, конечно же, является своего рода тупиковой ситуацией. Поэтому многие исследовательские лаборатории (например, компания IBM) предпочли сфокусировать свое внимание на других идеях альтернативных компьютеров, таких как углеродные нанотрубки и квантовые компьютеры.
После эксперимента Эдлмана было проведено множество других исследований возможностей ДНК-вычислений. Например, можно вспомнить опыт Э.Шапиро: в нем был реализован конечный автомат, который может находиться в двух состояниях: S0 и S1 - и отвечает на вопрос: четное или нечетное количество символов содержится во входной последовательности символов.
Сегодня ДНК-вычисления - это не более чем перспективные технологии на уровне лабораторных исследований, причем в таком состоянии они будут находиться еще не один год. Фактически на современном этапе развития необходимо ответить на следующий глобальный вопрос: какой класс задач поддается решению при помощи ДНК и можно ли построить общую модель ДНК-вычислений, пригодную как для реализации, так и для использования?
Химический состав ДНК и её макромолекулярная организация. Типы спиралей ДНК. Молекулярные механизмы рекомбинации, репликации и репарации ДНК. Понятие о нуклеазах и полимеразах. Репликация ДНК как условие передачи генетической информации потомкам. Общая характеристика процесса репликации. Действия, происходящие в вилке репликации. Репликация теломеров, теломераза. Значение недорепликации конечных фрагментов хромосом в механизме старения. Системы исправления ошибок репликации. Корректорские свойства ДНК-полимераз. Механизмы репарации поврежденной ДНК. Понятие о заболеваниях репарации ДНК. Молекулярные механизмы общей генетической рекомбинации. Сайт-специфическая рекомбинация. Генная конверсия.
В 1865г. Грегор Мендель открыл гены, а его современник Фридрих Мишер в 1869г. открыл нуклеиновые кислоты (в ядрах клеток гноя и сперматозоидов лосося). Однако долго еще эти открытия не связывали друг с другом, долго еще структуру и природу вещества наследственности не знали. Генетическая роль НК была установлена после открытия и объяснения явлений трансформации (1928, Ф.Гриффитс; 1944, О. Эвери), трансдукции (1951, Ледерберг, Циндер) и размножения бактериофагов (1951, А. Херши, М. Чейз).
Трансформация, трансдукция и размножение бактериофагов убедительно доказали генетическую роль ДНК. У РНК - содержащих вирусов (СПИДа, гепатита В, гриппа, ВТМ, лейкоза мышей и др.) эту роль выполняет РНК.
Строение нуклеиновых кислот . НК - биополимеры, участвующие в хранении и передаче генетической информации. Мономеры НК - нуклеотиды, состоящие из азотистого основания, моносахарида и одной или нескольких фосфатных групп. В составе НК все нуклеотиды являются монофосфатами. Нуклеотид без фосфатной группы называется нуклеозидом. Сахар, входящий в состав НК, представляет собой D-изомер и β-аномер рибозы или 2-дезоксирибозы. Нуклеотиды, содержащие рибозу, называются рибонуклеотидами и являются мономерами РНК, а нуклеотиды - производные дезоксирибозы, являются дезоксирибонуклеотидами, и из них состоит ДНК. Азотистые основания бывают двух типов: пурины - аденин, гуанин и пиримидины - цитозин, тимин, урацил. В состав РНК и ДНК входят аденин, гуанин, цитозин; урацил встречается только в РНК, а тимин только в ДНК.
В ряде случаев в НК присутствуют редко встречающиеся минорные нуклеотиды, такие как дигидроуридин, 4-тиоуридин, инозин и др. Разнообразие их особенно велико у тРНК. Минорные нуклеотиды образуются в результате химических превращений оснований НК, происходящих уже после образования полимерной цепи. Чрезвычайно распространены в РНК и ДНК различные метилированные производные: 5-метилуридин, 5-метилцитидин, l-N-метиладенозин, 2-И-метилгуанозин. У РНК объектом метилирования могут быть и 2"-гидроксигруппы остатков рибозы, что приводит к образованию 2"-О-метилцитидина или 2"-О-метилгуанозина.
Рибонуклеотидные и дезоксирибонуклеотидные звенья соединяются между собой с помощью фосфодиэфирных мостиков, связывающих 5"-гидроксильную группу одного нуклеотида с 3"-гидроксильной группой следующего. Таким образом, регулярная основная цепь образована фосфатными и рибозными остатками, а основания присоединены к сахарам подобно тому, как присоединены боковые группы в белках. Порядок следования оснований вдоль цепи называется первичной структурой НК. Последовательность оснований принято читать в направлении от 5"- к 3"- углеродному атому пентозы.
Структура ДНК. Модель структуры ДНК в виде двойной спирали была предложена Уотсоном и Криком в 1953 г (рис.7).
Согласно этой трехмерной модели, молекула ДНК состоит из двух противоположно направленных полинуклеотидных цепей, которые относительно одной и той же оси образуют правую спираль. Азотистые основания находятся внутри двойной спирали, и их плоскости перпендикулярны основной оси, а сахарофосфатные остатки экспонированы наружу. Между основаниями образуются специфические Н-связи: аденин - тимин (или урацил), гуанин - цитозин, получившие название уотсон-криковского спаривания. В результате более объемные пурины всегда взаимодействуют с пиримидинами, имеющими меньшие размеры, что обеспечивает оптимальную геометрию остова. Антипараллельные цепи двойной спирали не являются идентичными ни по последовательности оснований, ни по нуклеотидному составу, но они комплементарны друг другу именно благодаря наличию специфического водородного связывания между указанными выше основаниями.
Комплементарность очень важна для копирования (репликации) ДНК. Соотношения между числом различных оснований в ДНК, выявленные
Рис.7. В - форма ДНК
Чарграффом с соавт. в 50-х гг., имели большое значение для установления структуры ДНК: было показано, что число адениновых остатков в основаниях цепи ДНК, независимо от организма, равно числу тиминовых, а число гуаниновых - числу цитозиновых. Эти равенства являются следствием избирательного спаривания оснований (рис.8).
Геометрия двойной спирали такова, что соседние пары оснований находятся друг от друга на расстоянии 0.34 нм и повернуты на 36° вокруг оси спирали. Следовательно, на один виток спирали приходится 10 пар оснований, и шаг спирали равен 3.4 нм. Диаметр двойной спирали равен 20 нм и в ней образуются два желобка - большой и малый. Это связано с тем, что сахарофосфатный остов расположен дальше от оси спирали, чем азотистые основания.
Стабильность структуры ДНК обусловлена разными типами взаимодействия, среди которых основными являются Н-связи между основаниями и межплоскостное взаимодействие (стэкинг). Благодаря последнему обеспечиваются не только выгодные ван-дер-ваальсовы контакты между атомами, но и возникает

Рис.8. Принцип комплементарности и антипараллельности цепей ДНК
дополнительная стабилизация вследствие перекрывания р-орбиталей атомов параллельно расположенных оснований. Стабилизации способствует также благоприятный гидрофобный эффект, проявляющийся в защищенности малополярных оснований от непосредственного контакта с водной средой. Напротив, сахарофосфатный остов с его полярными и ионизированными группами экспонирован, что также стабилизирует структуру.
Для ДНК известны четыре полиморфные формы: А, В, С и Z. Обычной структурой является В-ДНК, в которой плоскости пар оснований перпендикулярны оси двойной спирали (рис.7.). В А-ДНК плоскости пар оснований повернуты примерно на 20° от нормали к оси правой двойной спирали; на виток спирали здесь приходится 11 пар оснований. В С-ДНК на витке спирали 9 пар оснований. Z-ДНК - это левая спираль с 12 парами оснований на виток; плоскости оснований примерно перпендикулярны оси спирали. ДНК в клетке обычно находится в В-форме, но отдельные ее участки могут находиться в A, Z или даже в иной конформации.
Двойная спираль ДНК не застывшее образование, она находится в постоянном движении:
· деформируются связи в цепях;
· раскрываются и закрываются комплементарные пары оснований;
· ДНК взаимодействует с белками;
· если напряжение в молекуле велико, то она локально расплетается;
· правая спираль переходит в левую.
Различают 3 фракции ДНК:
1.Частоповторяемая (сателлитная) – до 106 копий генов (у мыши 10%). Она не участвует в синтезе белка; разделяет гены; обеспечивает кроссинговер; содержит транспозоны.
2.Слабоповторяемая – до 102 - 103 копий генов (у мыши 15%). Содержит гены синтеза т-РНК, гены синтеза белков рибосом и белков хроматина.
3.Уникальная (неповторяемая) – у мыши 75% (у человека 56%). Состоит из структурных генов.
Локализация ДНК: 95 % ДНК локализуется в ядре в хромосомах (линейные ДНК) и 5 % - в митохондриях, пластидах и клеточном центре в виде кольцевой ДНК.
Функции ДНК : хранение и передача информации; репарация; репликация.
Две цепи ДНК в области гена принципиально различаются по своей функциональной роли: одна из них является кодирующей, или смысловой, вторая - матричной.
Это значит, что в процессе «считывания» гена (транскрипции или синтеза пре-мРНК) в качестве матрицы выступает матричная цепь ДНК. Продукт же этого процесса-пре-мРНК - по последовательности нуклеотидов совпадает с кодирующей цепью ДНК (с заменой тиминовых оснований на урациловые).
Таким образом, получается, что с помощью матричной цепи ДНК при транскрипции воспроизводится в структуре РНК генетическая информация кодирующей цепи ДНК.
Главными матричными процессами, присущими всем живым организмам, являются репликация ДНК, транскрипция и трансляция.
Репликация - процесс, при котором информация, закодированная в последовательности оснований молекулы родительской ДНК, передается с максимальной точностью дочерней ДНК. При полуконсервативной репликации дочерние клетки первого поколения получают одну цепь ДНК от родителей, а вторая цепь является вновь синтезированной. Процесс осуществляется при участии ДНК-полимераз, которые относятся к классу трансфераз. Роль матрицы играют разделенные цепи двунитевой материнской ДНК, а субстратами являются дезоксирибонуклеозид-5"-трифосфаты.
Транскрипция - процесс переноса генетической информации от ДНК к РНК. Все виды РНК - мРНК, рРНК и тРНК - синтезируются в соответствии с последовательностью оснований в ДНК, служащей матрицей. Транскрибируется только одна, так называемая «+»-цепь ДНК. Процесс протекает при участии РНК-полимераз. Субстратами являются рибонуклеозид-5"-трифосфаты.
Процессы репликации и транскрипции у прокариот и эукариот существенно различаются по скорости протекания и по отдельным механизмам.
Трансляция - процесс декодирования мРНК, в результате которого информация с языка последовательности оснований мРНК переводится на язык аминокислотной последовательности белка. Осуществляется трансляция на рибосомах, субстратами являются аминоацил-тРНК.
Матричный синтез ДНК, катализируемый ДНК-полимеразами, выполняет две основные функции: репликацию ДНК - синтез новых дочерних цепей и репарацию двунитевых ДНК, имеющих разрывы в одной из цепей, образовавшихся в результате вырезания нуклеазами поврежденных участков этой цепи. У прокариот и эукариот существует три разновидности ДНК-полимераз. У прокариот выделены полимеразы I, II и III типов, обозначаемые как pol l, pol ll и pol III. Последняя катализирует синтез растущей цепи, pol играет важную роль в процессе созревания ДНК, функции pol ll изучены не полностью. В эукариотических клетках в репликации хромосом участвует ДНК-полимераза ά, в репарации - ДНК-полимераза β, а γ разновидность является ферментом, осуществляющим репликацию ДНК митохондрий. Эти Ферменты, независимо от типа клеток, в которых происходит репликация, присоединяют нуклеотид к ОН-группе на З"-конце одной из цепей ДНК, которая растет в направлении 5"→3. Поэтому говорят, что данные Ф обладают 5"→3"-полимеразной активностью. Помимо этого все они проявляют способность деградировать ДНК, отщепляя, нуклеотиды в направлении 3"→5, т. е. являются 3"→5"-экзонуклеазами.
В 1957 г. Мезельсон и Сталь, изучая E. coli установили, что на каждой свободной цепи фермент ДНК-полимераза строит новую, комплементарную цепь. Это полуконсервативный способ репликации: одна цепь старая – другая новая!
Обычно репликация начинается в строго определенных участках, получивших название участков ori (от origin of replication), и от этих участков распространяется в обе стороны. Участкам ori предшествуют точки разветвления материнских цепей ДНК. Участок, примыкающий к точке разветвления, получил название репликативной вилки (рис.9). В ходе синтеза репликативная вилка перемещается вдоль молекулы, при этом расплетаются все новые участки родительской ДНК до тех пор, пока вилка не дойдет до точки терминации. Разделение цепей достигается с помощью специальных Ф - геликаз (топоизомераз). Энергия, необходимая для этого, высвобождается за счет гидролиза АТФ. Геликазы перемещаются вдоль полинуклеотидных цепей в двух направлениях.
Для начала синтеза ДНК необходима затравка - праймер. Роль праймера выполняет короткая РНК (10-60 нуклеотидов). Она синтезируется комплементарно определенному участку ДНК при участии праймазы. После образования праймера в работу включается ДНК-полимераза. В отличие от геликаз ДНК-полимеразы могут перемещаться только от 3" к 5" концу матрицы. Поэтому элонгация растущей цепи по мере раскручивания двунитевой материнской ДНК может идти только вдоль одной цепи матрицы, той, относительно которой вилка репликации движется от 3" к 5" концу. Непрерывно синтезируемая цепь получила название лидирующей. Синтез на запаздывающей цепи также начинается с образования праймера и идет в направлении, противоположном ведущей цепи - от вилки репликации. Запаздывающая цепь синтезируется фрагментарно (в виде фрагментов Оказаки), т. к. праймер образуется только тогда, когда вилка репликации освободит тот участок матрицы, который имеет сродство к праймазе. Лигирование (сшивание) фрагментов Оказаки с образованием единой цепи носит название процесса созревания.
При созревании цепи РНК-затравка удаляется как с 5" конца ведущей цепи, так и с 5" концов фрагментов Оказаки, а эти фрагменты сшиваются друг с другом. Удаление затравки осуществляется при участии 3"→5" экзонуклеазы. Этот же Ф вместо удаленной РНК присоединяет дезоксинуклеотиды, используя свою 5"→3" полимеразную активность. При этом в случае присоединения «неправильного» нуклеотида осуществляется «корректорская правка» - удаление оснований, образующих некомплементарные пары. Этот процесс обеспечивает чрезвычайно высокую точность репликации, отвечающую одной ошибке на 109 пар оснований.
Рис.9. Репликация ДНК:
1 - репликативная вилка, 2 - ДНК-полимераза (pol I - созревание);
3 - ДНК-полимераза (pol III - «корректорская правка»); 4-геликаза;
5-гираза (топоизомераза); 6-белки, дестабилизирующие двойную спираль.
Коррекция осуществляется в тех случаях, когда к З"-концу растущей цепи присоединяется «неправильный» нуклеотид, неспособный образовать нужные водородные связи с матрицей. Когда pol III ошибочно присоединяет неправильное основание, «включается» ее 3" -» 5"-экзонуклеазная активность, и это основание немедленно удаляется, после чего восстанавливается полимеразная активность. Такой простой механизм действует благодаря тому, что pol III способна работать как полимераза лишь на совершенной двойной спирали ДНК с абсолютно правильным спариванием оснований.
Еще один механизм удаления РНК-фрагментов основан на присутствии в клетках особой рибонуклеазы, получившей название РНКазы Н. Этот Ф специфичен к двунитевым структурам, построенным из одной рибонуклеотидной и одной дезоксирибонуклеотидной цепи, причем он гидролизует первую из них.
РНКаза Н также способна удалять РНК-праймер с последующей застройкой разрыва с помощью ДНК-полимеразы. На заключительных этапах сборки фрагментов в нужном порядке действует ДНК-лигаза, катализирующая образование фосфодиэфирной связи.
Раскручивание геликазами части двойной спирали ДНК в хромосомах эукариот приводит к сверхспирализации остальной части структуры, что неизбежно сказывается на скорости процесса репликации. Сверхспирализации препятствуют ДНК-топоизомеразы.
Таким образом, в репликации ДНК, помимо ДНК-полимеразы, принимает участие большой набор Ф: геликаза, праймаза, РНКаза Н, ДНК-лигаза и топоизомераза. Этим перечень Ф и белков, участвующих в матричном биосинтезе ДНК, далеко не исчерпывается. Однако многие из участников этого процесса до настоящего времени остаются мало изученными.
В процессе репликации происходит «корректорская правка» - удаление неправильных (образующих некомплементарные пары) оснований, включенных во вновь синтезированную ДНК. Этот процесс обеспечивает чрезвычайно высокую точность репликации, отвечающую одной ошибке на 109 пар оснований.
Теломеры. В 1938г. классики генетики Б.Мак-Клинтон и Г. Мёллер доказали, что на концах хромосом есть специальные структуры, которые назвали теломерами (телос-конец, мерос-часть).
Ученые обнаружили, что при воздействии рентгеновским облучением устойчивость проявляют лишь теломеры. Напротив, лишенные концевых участков, хромосомы начинают сливаться, что ведет к тяжелым генетическим аномалиям. Т.о., теломеры обеспечивают индивидуальность хромосом. Теломеры плотно упакованы (гетерохроматин) и малодоступны для ферментов (теломеразы, метилазы, эндонуклеаз и др.)
Функции теломер.
1.Механические: а) соединение концов сестринских хроматид после S-фазы; б) фиксация хромосом к ядерной мембране, что обеспечивает конъюгацию гомологов.
2.Стабилизационные: а) предохранение от недорепликации генетически значимых отделов ДНК (теломеры не транскрибируются); б) стабилизация концов разорванных хромосом. У больных α - талассемией в генах α - глобина происходят разрывы хромосомы 16д и к поврежденному концу добавляются теломерные повторы (ТТАГГГ).
3.Влияние на экспрессию генов. Активность генов, расположенных рядом с теломерами, снижена. Это проявление сайленсинга – транскрипционное молчание.
4.«Счетная функция». Теломеры выступают в качестве часового устройства, которое отсчитывает количество делений клетки. Каждое деление укорачивает теломеры на 50-65 н.п. А всего их длина в клетках эмбриона человека составляет 10-15 тысяч н.п.
Теломерная ДНК попала в поле зрения биологов совсем недавно. Первые объекты исследования – одноклеточные простейшие – ресничная инфузория (тетрахимена), которая содержит несколько десятков тысяч очень мелких хромосом и, значит, множество теломер в одной клетке (у высших эукариот менее 100 теломер на клетку).
В теломерной ДНК инфузории многократно повторяются блоки из 6-ти нуклеотидных остатков. Одна цепь ДНК содержит блок 2 тимин – 4 гуанин (ТТГГГГ - Г-цепь), а комплементарная цепь - 2 аденин – 4 цитозин (ААЦЦЦЦ - Ц-цепь).
Каково же было удивление ученых, когда обнаружили, что теломерная ДНК человека отличается от таковой у инфузории всего лишь одной буквой и образует блоки 2 тимин – аденин – 3 гуанин (ТТАГГГ). Более того, оказалось, что из ТТАГГГ - блоков построены теломеры (Г – цепь) всех млекопитающих, рептилий, амфибий, птиц и рыб.
Впрочем, удивляться здесь нечему, так как в теломерной ДНК не закодировано никаких белков (она не содержит гены). У всех организмов теломеры выполняют универсальные функции, речь о которых шла выше. Очень важная характеристика теломерных ДНК – их длина. У человека она колеблется от 2 до 20 тысяч пар оснований, а у некоторых видов мышей может достигать сотен тысяч н.п. Известно, что около теломер есть специальные белки, обеспечивающие их работу и участвующие в построении теломер.
Доказано, что для нормального функционирования каждая линейная ДНК должна иметь две теломеры: по одной теломере на каждый конец.
У прокариот теломеров нет – их ДНК замкнута в кольцо.
План рождения человека готов тогда, когда половые клетки матери и отца сливаются в одно целое. Такое образование называется зиготой или оплодотворённой яйцеклеткой. Сам же план развития организма заключён в молекуле ДНК , находящейся в ядре этой единственной клетки. Именно в ней закодирован цвет волос, рост, форма носа и всё остальное, что делает личность индивидуальной.
Конечно, судьба человека зависит не только от молекулы, но и от многих других факторов. Но гены, заложенные при рождении, тоже во многом влияют на судьбоносный путь. А представляют они собой последовательность нуклеотидов.
При каждой делении клетки ДНК удваивается. Поэтому каждая клетка несёт в себе информацию о строении всего организма. Это как если бы при строительстве кирпичного здания на каждом кирпиче имелся архитектурный план всего сооружения. Посмотрел всего лишь на один кирпич и уже знаешь, частью какой строительной конструкции он является.
Подлинная структура молекулы ДНК была впервые продемонстрирована британским биологом Джоном Гёрдоном в 1962 году. Он брал ядро клетки из кишечника лягушки и с помощью микрохирургической техники пересаживал его в лягушачью икринку. При этом в этой икринке собственное ядро было предварительно убито ультрафиолетовым облучением.
Из гибридной икринки вырастала нормальная лягушка. При этом она была абсолютно идентична той, чьё клеточное ядро было взято. Так было положено начало эре клонирования. А первым успешным результатом клонирования среди млекопитающих стала овечка Долли. Она прожила 6 лет, а затем скончалась.
Впрочем, сама природа тоже создаёт двойников. Случается это тогда, когда после первого деления зиготы две новые клетки не остаются вместе, а расходятся в стороны, и из каждой получается свой организм. Так рождаются однояйцевые близнецы. Их молекулы ДНК абсолютно одинаковые, поэтому близнецы так похожи.
Своим внешним видом ДНК напоминает верёвочную лестницу, завитую в правую спираль. А состоит она из полимерных цепочек, каждая из которых формируется из звеньев 4-х типов: адениновое (А), гуаниновое (Г), тиминовое (Т) и цитозиновое (Ц).
Именно в их последовательности и заключена генетическая программа любого живого организма. На рисунке ниже, для примера, приведён нуклеотид Т. У него верхнее кольцо называется азотистым основанием, пятичленное кольцо внизу представляет собой сахар, а слева находится фосфатная группа.
На рисунке изображён тиминовый нуклеотид, входящий в состав ДНК. Остальные 3 нуклеотида имеют сходное строение, а различаются по азотистому основанию. Правое верхнее кольцо - азотистое основание. Нижнее пятичленное кольцо - сахар. Левая группа РО - фосфат
Размеры молекулы ДНК
Диаметр двойной спирали составляет 2 нм (нм - нанометр, равен 10 -9 метра). Расстояние между соседними парами оснований вдоль спирали составляет 0,34 нм. Полный оборот двойная спираль делает через 10 пар. А вот длина зависит от того организма, которому принадлежит молекула. У простейших вирусов имеется всего лишь несколько тысяч звеньев. У бактерий их несколько миллионов. А у высших организмов их миллиарды.
Если вытянуть в одну линию все ДНК, заключённые в одной клетке человека, то получится нить длиной примерно 2 м. Отсюда видно, что длина нити в миллиарды раз больше её толщины. Чтобы лучше представить себе размеры молекулы ДНК, можно вообразить, что её толщина равна 4 см. Такой нитью, взятой из одной человеческой клетки, можно опоясать земной шар по экватору. В таком масштабе человек будет соответствовать размерам Земли, а ядро клетки вырастит до размеров стадиона.
Верна ли модель Уотсона и Крика?
Рассматривая структуру молекулы ДНК, возникает вопрос, как она, имея такую огромную длину, располагается в ядре. Она должна лежать так, чтобы быть доступной по всей своей длине для РНК-полимеразы, которая считывает нужные гены.
А как осуществляется репликация? Ведь после удвоения две комплементарные цепи должны разойтись. Это довольно сложно, так как цепи первоначально закручены в спираль.
Такие вопросы изначально породили сомнения в верности модели Уотсона и Крика . А данная модель была слишком конкретна и просто дразнила специалистов своей незыблемостью. Поэтому все бросились искать изъяны и противоречия.
Одни специалисты предполагали, что если злополучная молекула состоит из 2-х полимерных цепочек, связанных слабыми нековалентными связями, то они должны расходиться при нагревании раствора, что можно легко проверить экспериментально.
Вторые специалисты заинтересовались азотистыми основаниями, которые образуют друг с другом водородные связи. Это можно проверить, измеряя спектры молекулы в инфракрасной области.
Третьи специалисты думали, что если внутри двойной спирали и впрямь запрятаны азотистые основания, то можно выяснить, действуют ли на молекулу те вещества, которые способны реагировать только с этими запрятанными группами.
Было поставлено множество опытов и к концу 50-х годов XX столетия стало ясно, что предложенная Уотсоном и Криком модель выдерживает все испытания. Попытки её опровержения потерпели неудачу .
Молекула ДНК состоит из двух нитей, образующих двойную спираль. Впервые ее структура была расшифрована Френсисом Криком и Джеймсом Уотсоном в 1953 году.
Поначалу молекула ДНК, состоящая из пары нуклеотидных, закрученных друг вокруг друга цепочек, порождала вопросы о том, почему именно такую форму она имеет. Ученые назвали этот феномен комплементарностью, что означает, что в ее нитях друг напротив друга могут находиться исключительно определенные нуклеотиды. К примеру, напротив тимина всегда стоит аденин, а напротив цитозина - гуанин. Эти нуклеотиды молекулы ДНК и называются комплементарными.
Схематически это изображается так:
Т — А
Ц — Г
Данные пары образуют химическую нуклеотидную связь, которая определяет порядок расстановки аминокислот. В первом случае она немного слабее. Связь между Ц и Г более прочная. Некомплементарные нуклеотиды между собой пары не образуют.
О строении
Итак, строение молекулы ДНК особое. Такую форму она имеет неспроста: дело в том, что количество нуклеотидов очень большое, и для размещения длинных цепочек необходимо много места. Именно по этой причине цепочкам присуще спиральное закручивание. Это явление названо спирализацией, оно позволяет нитям укорачиваться где-то в пять-шесть раз.
Некоторые молекулы такого плана организм использует очень активно, другие - редко. Последние, помимо спирализации, подвергаются еще и такой «компактной упаковке», как суперспирализация. И тогда длина молекулы ДНК уменьшается в 25-30 раз.

Что такое «упаковка» молекулы?
В процессе суперспирализации задействуются гистоновые белки. Они имеют структуру и вид катушки для ниток или стержня. На них и наматываются спирализованные нити, которые становятся сразу «компактно упакованными» и занимают мало места. Когда возникает необходимость использования той или иной нити, она сматывается с катушки, к примеру, гистонового белка, и спираль раскручивается в две параллельные цепочки. Когда молекула ДНК пребывает именно в таком состоянии, с нее можно считывать необходимые генетические данные. Однако есть одно условие. Получение информации возможно, только если структура молекулы ДНК имеет раскрученный вид. Хромосомы, доступные для считывания, называются эухроматинами, а если они суперсипирализованы, то это уже гетерохроматины.
Нуклеиновые кислоты
Нуклеиновые кислоты, как и белки, являются биополимерами. Главная функция - это хранение, реализация и передача наследственной (генетической информации). Они бывают двух типов: ДНК и РНК (дезоксирибонуклеиновые и рибонуклеиновые). Мономерами в них выступают нуклеотиды, каждый из которых имеет в своем составе остаток фосфорной кислоты, пятиуглеродный сахар (дезоксирибоза/рибоза) и азотистое основание. В ДНК код входит 4 вида нуклеотидов - аденин (А)/ гуанин (Г)/ цитозин (Ц)/ тимин (Т). Они отличаются по содержащемуся в их составе азотистому основанию.
В молекуле ДНК количество нуклеотидов может быть огромным - от нескольких тысяч до десятков и сотен миллионов. Рассмотреть такие гигантские молекулы можно через электронный микроскоп. В этом случае удастся увидеть двойную цепь из полинуклеотидных нитей, которые соединены между собой водородными связями азотистых оснований нуклеотидов.

Исследования
В ходе исследований ученые обнаружили, что виды молекул ДНК у разных живых организмов отличаются. Также было установлено, что гуанин одной цепи может связываться только лишь с цитозином, а тимин - с аденином. Расположение нуклеотидов одной цепи строго соответствует параллельной. Благодаря такой комплементарности полинуклеотидов молекула ДНК способна к удвоению и самовоспроизведению. Но сначала комплементарные цепи под воздействием специальных ферментов, разрушающих парные нуклеотиды, расходятся, а затем в каждой из них начинается синтез недостающей цепи. Это происходит за счет имеющихся в большом количестве в каждой клетке свободных нуклеотидов. В результате этого вместо «материнской молекулы» формируются две «дочерние», идентичные по составу и структуре, и ДНК-код становится исходным. Данный процесс является предшественником клеточного деления. Он обеспечивает передачу всех наследственных данных от материнских клеток дочерним, а также всем последующим поколениям.
Как читается генный код?
Сегодня вычисляется не только масса молекулы ДНК - можно узнать и более сложные, ранее не доступные ученым данные. Например, можно прочитать информацию о том, как организм использует собственную клетку. Конечно, сначала сведения эти находятся в закодированном виде и имеют вид некой матрицы, а потому ее необходимо транспортировать на специальный носитель, коим выступает РНК. Рибонуклеиновой кислоте под силу просачиваться в клетку через мембрану ядра и уже внутри считывать закодированную информацию. Таким образом, РНК - это переносчик скрытых данных из ядра в клетку, и отличается она от ДНК тем, что в её состав вместо дезоксирибозы входит рибоза, а вместо тимина - урацил. Кроме того, РНК одноцепочная.

Синтез РНК
Глубокий анализ ДНК показал, что после того как РНК покидает ядро, она попадает в цитоплазму, где и может быть встроена как матрица в рибосомы (специальные ферментные системы). Руководствуясь полученной информацией, они могут синтезировать соответствующую последовательность белковых аминокислот. О том, какую именно разновидность органического соединения необходимо присоединить к формирующейся белковой цепи, рибосома узнает из триплетного кода. Каждой аминокислоте соответствует свой определенный триплет, который ее и кодирует.
После того как формирование цепочки завершено, она приобретает конкретную пространственную форму и превращается в белок, способный осуществлять свои гормональные, строительные, ферментные и иные функции. Для любого организма он является генным продуктом. Именно из него определяются всевозможные качества, свойства и проявления генов.

Гены
В первую очередь процессы секвенирования разрабатывались с целью получения информации о том, сколько генов имеет структура молекулы ДНК. И, хотя исследования позволили ученым далеко продвинуться в этом вопросе, узнать точное их количество пока что не представляется возможным.
Еще несколько лет назад предполагалось, что молекулы ДНК содержат приблизительно 100 тыс. генов. Немного погодя цифра уменьшилась до 80 тысяч, а в 1998 г. генетиками было заявлено, что в одной ДНК присутствует только 50 тысяч генов, которые являются всего лишь 3 % всей длины ДНК. Но поразили последние заключения генетиков. Теперь они утверждают, что в геном входит 25-40 тысяч упомянутых единиц. Получается, что за кодирование белков отвечает только 1,5 % хромосомной ДНК.
На этом исследования не прекратились. Параллельная команда специалистов генной инженерии установила, что численность генов в одной молекуле составляет именно 32 тысячи. Как видите, получить окончательный ответ пока что невозможно. Слишком много противоречий. Все исследователи опираются только на свои полученные результаты.
Было ли эволюционирование?
Несмотря на то что нет никаких доказательств эволюции молекулы (так как строение молекулы ДНК хрупкое и имеет малый размер), все же учеными было высказано одно предположение. Исходя из лабораторных данных, они озвучили версию следующего содержания: молекула на начальном этапе своего появления имела вид простого самовоспроизводящегося пептида, в состав которого входило до 32 аминокислот, содержащихся в древних океанах.
После саморепликации, благодаря силам естественного отбора, у молекул появилась способность защищать себя от воздействия внешних элементов. Они стали дольше жить и воспроизводиться в больших количествах. Молекулы, нашедшие себя в липидном пузыре, получили все шансы для самовоспроизведения. В результате череды последовательных циклов липидные пузыри приобрели форму клеточных мембран, а уже далее - всем известных частиц. Следует отметить, что сегодня любой участок молекулы ДНК представляет собой сложную и четко функционирующую структуру, все особенности которой учеными до конца еще не изучены.

Современный мир
Недавно ученые из Израиля разработали компьютер, которому под силу выполнять триллионы операций в секунду. Сегодня это самая быстрая машина на Земле. Весь секрет заключается в том, что инновационное устройство функционирует от ДНК. Профессора говорят, что в ближайшей перспективе такие компьютеры смогут даже вырабатывать энергию.
Специалисты из института Вейцмана в Реховоте (Израиль) год назад заявили о создании программируемой молекулярной вычислительной машины, состоящей из молекул и ферментов. Ими они заменили микрочипы из кремния. К настоящему времени команда еще продвинулась вперед. Теперь обеспечить компьютер необходимыми данными и предоставить нужное топливо может всего одна молекула ДНК.
Биохимические «нанокомпьютеры» - это не выдумка, они уже существуют в природе и проявлены в каждом живом существе. Но зачастую они не управляются людьми. Человек пока что не может оперировать геном какого-либо растения, чтобы рассчитать, скажем, число «Пи».
Идея об использовании ДНК для хранения/обработки данных впервые посетила светлые головы ученных в 1994 году. Именно тогда для решения простой математической задачи была задействована молекула. С того момента ряд исследовательских групп предложил различные проекты, касающиеся ДНК-компьютеров. Но здесь все попытки основывались только на энергетической молекуле. Невооруженным глазом такой компьютер не увидишь, он имеет вид прозрачного раствора воды, находящегося в пробирке. В нем нет никаких механических деталей, а только триллионы биомолекулярных устройств - и это только в одной капле жидкости!
ДНК человека
Какой вид у ДНК человека, людям стало известно в 1953 году, когда ученые впервые смогли продемонстрировать миру двухцепочную модель ДНК. За это Кирк и Уотсон получили Нобелевскую премию, так как данное открытие стало фундаментальным в 20 веке.
Со временем, конечно, доказали, что не только так, как в предложенном варианте, может выглядеть структурированная молекула человека. Проведя более детальный анализ ДНК, открыли А-, В- и левозакрученную форму Z-. Форма А- зачастую является исключением, так как образуется только в том случае, если наблюдается недостаточность влаги. Но это возможно разве что при лабораторных исследованиях, для естественной среды это аномально, в живой клетке такой процесс происходить не может.
Форма В- является классической и известна как двойная правозакрученная цепь, а вот форма Z- не только закручена в обратном направлении, влево, но также имеет более зигзагообразный вид. Учеными выделена еще и форма G-квадруплекс. В ее структуре не 2, а 4 нити. По мнению генетиков, возникает такая форма на тех участках, где имеется избыточное количество гуанина.

Искусственная ДНК
Сегодня уже существует искусственная ДНК, являющаяся идентичной копией настоящей; она идеально повторяет структуру природной двойной спирали. Но, в отличие от первозданного полинуклеотида, в искусственном - всего два дополнительных нуклеотида.
Так как дубляж создавался на основе информации, полученной в ходе различных исследований настоящей ДНК, то он также может копироваться, самовоспроизводиться и эволюционировать. Над созданием такой искусственной молекулы специалисты работали около 20 лет. В результате получилось удивительное изобретение, которое может пользоваться генетическим кодом так же, как и природная ДНК.
К четырем имеющимся азотистым основаниям генетики добавили дополнительные два, которые создали методом химической модификации естественных оснований. В отличие от природной, искусственная ДНК получилась достаточно короткой. Она содержит только 81 пару оснований. Тем не менее она также размножается и эволюционирует.
Репликация молекулы, полученной искусственным путем, имеет место благодаря полимеразной цепной реакции, но пока что это происходит не самостоятельно, а через вмешательство ученых. В упомянутую ДНК они самостоятельно добавляют необходимые ферменты, помещая ее в специально подготовленную жидкую среду.
Конечный результат
На процесс и конечный итог развития ДНК могут влиять различные факторы, например мутации. Это обуславливает обязательное изучение образцов материи, чтобы результат анализов был достоверным и надежным. В качестве примера можно привести тест на отцовство. Но не может не радовать, что такие казусы, как мутация, встречаются редко. Тем не менее образцы материи всегда перепроверяют, чтобы на основе анализа получить более точную информацию.

ДНК растений
Благодаря высоким технологиям секвенирования (HTS) совершена революция и в области геномики - выделение ДНК из растений также возможно. Конечно, получение из растительного материала молекулярной массы ДНК высокого качества вызывает некоторые трудности, обусловленные большим числом копий митохондрий и хлоропластов ДНК, а также высоким уровнем полисахаридов и фенольных соединений. Для выделения рассматриваемой нами структуры в этом случае задействуются самые разные методы.
Водородная связь в ДНК
За водородную связь в молекуле ДНК отвечает электромагнитное притяжение, создаваемое между положительно заряженным атомом водорода, который присоединен к электроотрицательному атому. Данное дипольное взаимодействие не подпадает под критерий химической связи. Но она может осуществиться межмолекулярно либо в различных частях молекулы, т. е. внутримолекулярно.

Атом водорода присоединяется к электроотрицательному атому, являющемуся донором данной связи. Электроотрицательным атомом может быть азот, фтор, кислород. Он - путем децентрализации - привлекает к себе электронное облако из водородного ядра и делает атом водорода заряженным (частично) положительно. Так как размер Н маленький, по сравнению с другими молекулами и атомами, заряд получается также малым.
Расшифровка ДНК
Прежде чем расшифровать молекулу ДНК, ученные сначала берут огромное количество клеток. Для наиболее точной и успешной работы их необходимо около миллиона. Полученные в процессе изучения результаты постоянно сравнивают и фиксируют. Сегодня расшифровка генома - это уже не редкость, а доступная процедура.

Конечно, расшифровывать геном одной клетки - это нецелесообразное занятие. Полученные в ходе таких исследований данные для ученых не представляют никакого интереса. Но важно понимать, что все существующие на данный момент методы декодировки, несмотря на их сложность, недостаточно эффективны. Они позволят считывать только 40-70 % ДНК.
Однако гарвардские профессора недавно заявили о способе, благодаря которому можно расшифровать 90 % генома. Методика основана на добавлении к выделенным клеткам молекул-праймеров, с помощью них и начинается репликация ДНК. Но даже и этот метод нельзя считать успешным, его еще нужно доработать, прежде чем открыто использовать в науке.
